序編 プロローグ
ビジネスはすべてイノベーションとなってくる
3章
ヒトと環境はことばで切り結ぶ
1◇ヒトは6感・6種のセンサーで環境データを得る
物事や物事の作法を表現するには、まずその存在を知る必要がある。
ヒトは、生物物理的な五体をもって、環境に暮らす。その六感は、眼耳鼻舌身意とされ、そのセンサーが感じる対象は、色声香味触法と、般若心経では説かれている。
つまり、6官6種のセンサーで、環境から6次元のデータを受取っていると、インドの古代哲学者は考えていたようである。[3.1]
胎児は、胎内で、光を見、声や音楽を聴き、羊水を飲み、指をしゃぶりっていることが、超音波画像でわかってきた。お腹の中で 赤ちゃんは、手を振っていたり、よく口を開けたり.あくびをしたり羊水を飲んだり指しゃぶりをする。
6感目の意識については、強すぎる光には目を蔽い、うるさい音を避け、聞きなれた声や言語には五体で反応パターン(法)を示す様子までが判ってきた。[3.2]
つまり、物事や出来事の事実をリアル・ファクトとしたとき、それをデータとして捉え、何らかの記号で表現したものをリアル・ファクト・データとしよう。しかし、完全なファクト・データというものはない。それは、表現する手段がヒトの6感に感じられ、表現できる属性に限られるからである。
例えば、イヌは、散歩にでて、喜んで電柱の周りの臭いを嗅いで、そこを前に通ったイヌ達の残した記号を読み解いていると思われるが、我々人間には、その事実を伺い知ることはできない。
ヒトは、生活を豊かにするために、共同社会を作って、その秩序を進化させてきたが、社会を進化させるには、データの伝達技術が必要であった。語られた言葉データが物事の個々の事象を正しく記述し、正しく伝えることで、無駄を排除でき、社会が豊かになる基礎を得ることができる。
例えば美味しいもの、美しい景色、楽しいことなど、料理人や画家や音楽家ならいざ知らず、一般のヒトが、ほかのヒトにそれを伝えるとすれば、それは言葉しかない。
ヒトと環境に対峙したとき、切り結ぶ手段は、多次元で多様な意味を持った言葉である。
物事(リアル・ファクト)を時空を超えて正確に伝えようとすれば、テキストデータしかない。歴史上、ヒトが一番早い段階で、手に入れたリアル・ファクト・データは、言葉だった。
そして、ヒトが言葉を記録する手段として文字を発明したとき、歴史、つまり文明が始まった。書き言葉を記録するメディアという技術、つまり文字によるテキストの出現をもって紀元の元年としている。
ただ、話す言葉と書く文字との間には、大きな飛躍があった。
つまり、言葉の最初は子音からで、イスラーム系ではアラビア文字によるそれであり、やがて母音との組合せでワードがモノゴトを指し示すようになったようである。形象文字物事を示す形と音声の組合せから始まった様である。
記号としての文字をどのように社会がリテラシーとして、身に着けて行ったかは、それぞれの民族のまさに歴史のドラマで物語られている。
因みに、日本では、中国や朝鮮からもたらされた伝説和邇氏の伝説がある。これを習得し、それを権勢の基とした古代官僚には菅原道真がいる。当時は日本語を記録する術はなく、一端漢文に翻訳し、それを日本語に訳すのに専門職が求められ、道真は文章博士に任じられた。
それを日本のしゃべり言葉で記録し再生するリテラシーにもっとも貢献したのは、紀元1千年に書かれた紫式部の源氏物語である。源氏物語は、戦国大名の御姫様達に人気で、常陸の御姫様にはそのレンタル本を、能登の畠山の御姫様にはセルスルー本を、文化の最高位の三条西実隆が、写本してビジネスとしていたことが知られている。
こうして応仁の乱(1467年)ころになると、百姓上がりの木下藤吉郎まで、愛妻に戦場からラブレターを日本語で書いて、読み書きできるようになったのである。伊達正宗は18歳からの5年間で200本も書いた手紙が現存している。
そのため、日本の地震の記録は、DC1000以降の約1000年間で、10数回の記録の時間間隔分布データが、地震学会にとっても最も貴重なデータとなっている事実がある。つまり簡単な割り算で、平均100年に一度は、記録に残る大地震があることが分かるのである。
ちなみにラテン語化されたペルシャ語やギリシャ語の文献知識を日本人が自国語で自由に読み書きすることに壁があったように、遅れていた西欧の中でも進んでいたフランク王国のシャルル5世が、椅子に座ってしっかりと唇を閉じて黙読をしている姿が敬意をもって描かれたのは、14世紀のことで、王は自ら書簡に自ら手を入れ署名出来たといわれる。[3.3]
ただ、ヒトには、6感がある。古代インド哲学は、その6のセンサーとそれらがセンスする対象、ICTで言うところの6個のオブジェクトを定義している。
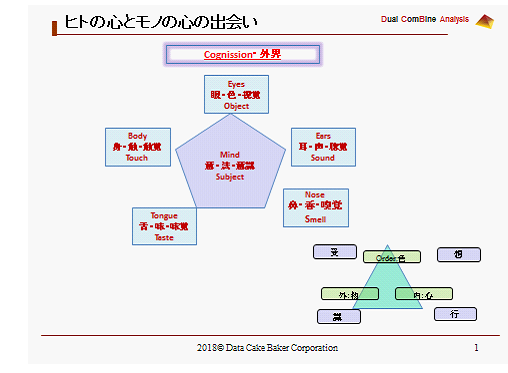
[図3.1]
ヒトが持って生まれた外界を察知し、感得できるセンサーは、眼、耳、鼻、舌、身、意の6種である。
その感知できるオブジェクトは、色、声、香、味、触、法である。
色は形あるもの、つまり目に映る物質の色や形態である。
声は耳に聞こえる音や声や言葉やセリフや音曲である。
香は、鼻腔に漂う香りや臭いである。
味は、舌に味わうことができる対象である。
触は、身体に直接触れる感触で、風合いやテクスチャーと呼ばれる。
法は、意に写るイメージである。
”イノベーションのはじめに言葉があった”とする例で、味覚は、興味深い。
各民族は、味覚について、いろいろな言葉で分類しているが、日本の”うま味”という言葉が、大きな産業に繋がったことは良く知られている。
例えば、アーユルヴェーダでは、甘味 - madhu(マドゥー)、 酸味 - amla(アムラ)、 塩味 - lavana(ラヴァナ)、 辛味 - katu(カトゥ)、苦味 - tikta(テクタ)、渋味 - kashaya(ケシャイ)を挙げている。
四川料理では、麻-痺れ、 辛味 - 辣、甘味 - 甜、塩味 - 鹹、酸味 - 酸と、苦み、香味を加えて七味している。中国の五行説では、5つで土・木・水・金・火の五行に対応して 酸味 - 木、苦味 - 火、甘味 - 土、辛味 - 金、塩味(鹹) - 水としている。
仏教では、牛や羊の乳を精製する過程における、五段階の味で、乳味、酪味、生酥味(しょうそみ)、熟酥味、醍醐味、醍醐味とは精製の段階を経て美味となった最高級の風味や乳製品を指し、このことから物事の真のおもしろさや仏教での衆生に例えられる(涅槃経による五味相生の譬)。
日本では、甘味、酸味、塩味、苦味、うま味とした。うま味は日本だけの言葉である。
「うま味」を追求した池田 菊苗がうま味成分の分子構造を突き止め、その製法特許を得た。これを鈴木三郎助が権利を得て、味の元を起こした。その見事な2ページの簡素な契約書は、川崎大師線の鈴木町の駅前のビルで見ることができる。
因みに、うま味をヒトが感じる舌の味蕾に存在する感覚細胞にグルタミン酸受容体が発見されたのはその後である。
ついでながら、触は、さらに微妙である。
触は、身体に直接触れる感触で、風合いやテクスチャーと呼ばれる。また力、振動、動き等、ハプテックスと呼ばれ、物の表面の質感・手触り、本来は織物の質感を意味する。髪型においては髪の表面の見た目の光沢や毛先の揃い方ばかりでなく、手で直接触った際の感触も含む総合的な概念。 コンピュータグラフィックスにおいて、3次元オブジェクト表面に貼り付けられる模様等にも使われる。
1ミクロンは、は目に見えないが、薬指の腹でさすって判別はできる。ヒトが絹の風合いの衣服に憧れ、古代ローマから中国までのシルクロードができたとされる。
また、香りもまた、文化が異なると変わるが、これは食に近いことがわかる。
五の臭い:羶(せん)(羊肉のなまぐさいにおい)・腥(せい)(生の肉のなまぐさいにおい)・香(よいにおい)・焦(こげたにおい)・朽(くさったにおい)。また、草木で、薜茘(へいれい)・白芷(びゃくし)・蘼蕪(びぶ)・椒(しょう)・蓮(れん)。
日本の香道では香木の香質を味覚にたとえて、辛(シン)・甘(カン)・酸(サン)・鹹(カン)・苦(ク)の5種類に分類し「五味」という。また、その含有樹脂の質と量の違いから以下の6種類に分類し、六国(りっこく)と称する。
木所と読み方として、伽羅 きゃら、羅国 らこく、真那伽 まなか、真南蛮 まなばん、佐曾羅 さそら、寸聞多羅 すもたら(すもんだら)。これらを総じて六国五味という。
問題が、意である。その対象となる法とは何かである。これは、この連環データ分析読本では、イメージとして、またこうした5感センサーでとらえた、環境情報が発してヒトが受け取った意味のあるデータのメッセージであると措定しておきたい。
デジタル化が進んで、目に見て空間を時間的に探索できるWebブラウザーはできたが、いずれその他の5感のブラウザーやマルチモーダルなブラウザーが開発されることになろう。ただ、その際、眼耳鼻舌身意の順序にも、意味があることを忘れてはならない。
2◇ヒトは複数の知性で外部環境に表現する
一方、情況対応欲求に関わる活動を実践する智慧は、各自がそれぞれ持って生まれている。
ヒトは、多様な多重知性で、表現し、環境と会話し、新しい状況を演出する。
教育を根底から考え直してディープ・アンダースタンディングを提案しているハワード・ガードナは、それを多重知能(Multiple Intelligences)と呼んで、現在は、8種を挙げている。[2.3][3.4]
ヒトは、従来のIQつまり知能指数だけではなく、いろいろな知能や知性があると主張している:
1.言語的知性
2.論理数学的知性
3.音楽的知性
4.身体運動的知性
5.空間的知性
6.対人的知性
7.内省的知性
8. 博物学、または環境知性
これらはいずれも、社会に対する何らかの働きかけができる天賦の知性であるという意味で、自らが、外部環境である社会に何らかのパフォーマンスを実践する能力であることがわかる。
いわば、これこそ、社会から頼みとされる役割であり、それを引き受け、実践する能力であると言える。つまり、各自が社会に貢献できるビジネスの実践力といえよう。
こうした多重知性こそが、社会を形成する基礎的な意味を生じさせ、社会環境に進化を生じさせる。
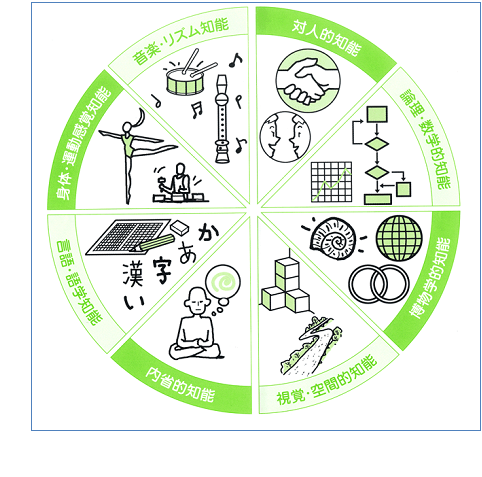
[図 3.2]
多重知性の説明図は、""8つの知能(MI)"で自分の可能性を見つめ直す" からの引用:http://www.nichinoken.co.jp/np5/nnk/multiple_intelligences/mi/mi.html
ちなみに、荘子の包丁の寓話を引いて“フロー”の概念を解いたチクセントミハイは、このH.ガードナーの学派に繋がる一人である。また、I.Q.に対し、エモーションに関するE.Q.を提唱してベストセラーとなったダニエル・ゴールドマンも、この学派に繋がっている。[3.5]
ところで、5体を持って外界を認識する般若心経の6感と、逆に外部に対して働きかける8個のMI’sは、対となっているが、般若心経にあってH.ガードナーに無いモノの1つに、舌と味に対するパフォーマンスの知性がある。
これぞまさしく、パテシエやソムリエやシェフ等の知性である。
ただ、H.ガードナーは、MI'sは、7つや8つに限らないと言って居られるので、いつか、提案して見たい。
3◇半導体から始まったデジタル環境の進化の本質
いま、社会は揺れている.従来の職場や企業が変化の波に洗われ、仕事の種類である職種や企業の立ち位置である業種や業界の壁が壊れている.
いわゆるDX化である。その流れを追ってみよう。そこでは一体何が流れ、何の形が、どのように変わってきたのであろうか?
昔いたタイピストや電話交換手等の職業は今は居なくなり、この間まで見かけた銀行のお札を数える姿や駅の改札や車掌さんも見かけなくなり、街では傘屋さんやミシン屋さんやカメラや自転車屋さんや電気屋さん等の専門店ばかりでなくデパート等も少なくなった.
一方、古本屋からはじまったアマゾンが、CDや化粧品やまさにデパートのように何でも売るようになり、どんな大きな本屋でも売っていない本を家に居ながら買うことができるようになった.また空いている自動車と乗りたいヒトを結んだり、空いている部屋と泊まりたい客を結んだビジネスや、遠い会社でなく、サテライトオフィスで働いたりするビジネスも身近になってきた.
こうした新しいビジネスは、サービスニーズとそのソリューションとして結びつける手段が出現したことにある.その手段は、いわゆるICT、つまり情報通信技術の発展だったが、ICTが、従来あった市場の機能を大きく変えてきたからだと言える.
市場は、売り手が持っているバラエティに富んだ商品やサービスを多く集め、一方それを求める消費者を多く集め、それらを繋いでマッチングさせ、取引と決済するプロセスを滑らかに実現してきた.ただ、規格品が溢れ、その稼働率が落ちる一方、サービスニーズが多様化している.そして、それらを結んでマッチングさせるソリューションがICTによって容易になっている.
デジタル化は、ベル研が開発したゲルマと不純物のアンチモンとしてソニーに技術供与されて始まったトランジスタを、信号処理のアナログのラジオの周波数を扱えるように、アンチモンをリンに入れ替えるプロセスを開発してパフォーマンスを挙げたのは、塚本哲男だった。
ただリンの濃度が上り過ぎ大量の不良品ができ、そのいわば不用品の利用法をデジタル化ならと考えたソニーの植村三良が、数値を計算する電卓から始まった。因みに余談ながら、塚本がその非良品となるリンのドープの限界の確認を頼まれたのが、江崎玲於奈で、それがノーベル賞に繋がった。
ソニーがオーディオから映像へとメディアタイプを広げたプロジェクトがマイクロテレビであった。そこではゲルマでは無く、耐電圧やより高周波の信号医処理ができるシリコンのトランジスタだった。それにガードリンクや中グリ等の多くの貢献した一人が川名喜之だった。
しかし、ソニーは信号処理から情報処理へとビジネスドメインを広げていったが、その先導役は、やはり映像の信号処理からであった。
その先駆けとなったのは、世界初のカセット型VTRの高速な記録をUマッチングを使った、ドキュメントのデータベースを構築し、検索するシステムを開発した中山正行だった。
これに目を着けたIBMがソニーから磁気記録の特許ライセンスを導入し、大型コンピュータの外部記憶装置の磁気テープを開発することになった。さらにダスドという磁気デスクに繋がり、メインフレームコンピュータの大躍進に繋がったのである。
信号処理の波形は正確でなくても、「0,1」の区別なら、余裕を持たせる設計なら、信号処理用の不良品でも、リアルタイムでなければ、使うことができる。
これを、音楽処理をするのに、高速で信号の記録再生を可能にしたベータマックスであった。これに目を着けたのが、中島平太郎で、その信号処理方式を開発したのが、ソニーの中で大崎工場と非線形処理の自主ゼミをやっていたソニーの芝浦工場の土井利忠等であった。
こうして、信号処理のデジタル化技術は、喜怒哀楽を人生にもたらすバーチャルな音楽産業から始まった。
この信号のデバイス間の転送速度を2メガビット/秒とした標準が、CDで登場し、その標準フォーマットが、デジタル世代の標準となった。
CD-Iである。その信号の見出し部分にあたるTOCのスペースを未定義にして、オープンとしたのは、ソニーの出井伸之とフィリップスであった。
そこに、音楽以外のテキスストや、数字やプログラム等を記録する約束事を決め、当時ソニーが世界で最も使い易いワープロと言われた自然言語処理体系のワードプロセサーの英語辞書を外部メモリーデバイスとして販売した。それは、パイオニアが開発していた静止画付きのレーザーディスクのファーマットを発展させたものであった。
これにより、3.5インチでは何十枚にもなる新しいOSでも1枚のCD-Iでプログラム配布が可能になって、マルチタスクでマルチウインドウのコンスーマ・プラットフォームが、実現することに繋った。
1994年暮れ11月に、ネットスケープ・ナビゲータのWebブラウザが登場すると、明けて1995年春には、あっという間に、世界中の16ビットPC上に、コンスーマ用ソフトプラットフォームが整い、インターネットが彗星のごとく登場した。
このとき、ビルゲーツは、夏にウィンドウズ95の発表を控えてマイクロソフトが倒産する危険を感じたと振り返っている。事実、OSの上にWebブラウザが大きくかぶさって、種々のアプリを実現してきたのである。
かくして、デジタル化は、データ、テキスト、プログラムはもちろん、音楽、画像、映像等のあらゆるデータタイプが処理できる新しい社会環境として登場させることになった。
外部環境のファクト・データは、デジタル化によって言葉、文字、数字、画像、映像など、多様なメディアタイプをデータ化し、記録、蓄積、再生、編集、配布する技術を発展させた。
それらに、広告反応行動、検索行動、ザッピング行動、購入行動等の行動属性とリンクする行動の推移の時系列ネットワークデータを取得することで、より豊かなデータが得られるようになってきた。
そのためのメディアとして、メディア自身が、エンターテインメント性や、ニュース性を持ち、かつインタラクティブ性を持ったリッチコンテンツになってきた。
つまり、パーソナル・メディアの電話のテレビ化によるマス・メディア化であり、マスメディアのテレビのパーソナル化としての電話化現象である。
また、これらのパーソナル・メディアとマス・メディアの代表的なリアルタイム・メディアの中間に、インターネットに代表されるニア・リアルタイムメディアが、ミディアム・マルチメディアとして登場してきた。[3.6]
こうして、ヒトを取り巻く環境は、自然環境から人工環境へと大きく変わってきた。
特に、それは、ヒトと環境の接点である、Webブラウザや、検索エンジンや、スマートスピーカ等のコア・アプリであり、それらが人々が要求するサービスソリューションの提供手段としての環境となってきている。
現在、AIで車の自動運転の技術が注目されている。こうした行動は、やはり文章のような情報処理をしていると考えられている。
例えば、自動車の運転行動を「その交差点を右に曲がって、緩やかに先行車に追従する」というように、ヒトはまず言語的に意味的なまとまりをもった単位に分節化して記述することができる。
さらに「交差点を右折する」際には、「まずブレーキを踏んで減速し、ステアリングを右に切り、アクセルを踏んで加速して新たな道に入り、ステアリングを元に戻してから、再度アクセルを踏んで加速する」と言った一連の動作を行う必要がある。
谷口らは、細かい動作を言語分析的に、第1分節として運転文字とよび、最初の分節を意味を持った運転単語と命名している。こうして得られる2重分節メカニズムを使った、実際の時系列データを得ることで、自動運転に必要な情報モデルが得られるとしている。
加えて、谷口は、眼耳鼻舌身意などの各センサー情報をモーダルと呼び、これらが現実には組み合わさって実現し、かつそれに反応行動を起こすことで、単にそれらの共起度だけでなく、時系列的に順序をもって起こるデータから、運転文字や運転単語を自己学習することができるとしている。[3.7]
ちょうどインタネットを始めとする各種のICTイノベーション現象が一斉に世界同意時に開花を始めた1995年ころ、日本では、産官のソフトの基盤研究の5年限定のプロジェクトがあった。
そこでは、インタネットブラウザやJAVAやオントロジー等多くの技術概念の開発を企図し膨大な特許を取得したが、ビジネスとしては、その半分以上をUSに先を越された。
しかし、未だ幾つかの未開発の技術概念のひとつに、「ホームサーバ」があり、それは、いま、アマゾンが家庭内に棲みこませつつある「スマートスピーカ」である。その目指す先は、食ブラウザーではなかろうか?
また料理はまさしく、マルチモーダルな優れたセンサーと、身体知性や空間知性や論理知性はもちろん、対人的知性などほぼすべてのMI'sが必要である。
もし、食サービスに関わるブラウザが開発できれば、生活だけでなく、産業構造や金融システムにまで及ぶに大きな変革をもたらすことになるだろう。もちろん今回のコロナ騒ぎもそのトリガーの一つとなるだろう。
このことが、あらゆるモノゴトをリンクするだけでなく、またあらゆるビジネスの組織形態の分解と再リンクをすることで、あらゆるビジネスのカテゴリーを崩壊し、再定義する大きなうねりを起こしている。
物事で構築された環境データは、リンクされネットワークされ、計算処理される新しい環境データとなり、ヒトはそうした新しい環境で、そこから意味のある情報を得て、役に立つ知識を生むという新しい仕事ができるようになった。
こうして、時代はデジタル化したメディアが、あらゆる事象をリンクし、ネットワークしたデータを構造化するための計算をし、ヒトとヒトを繋いでデータから意味のある情報を創発するアクティブ・メディアになった。こうして、デジタル化の本質は、データ化されたことで、意味のあるデータが創発される環境に人びとが取り囲まれそこに引きづり込まれたということであろう。
イノベーションが新しいイノベーションを生む時代となってきた。これは全て、半導体の信号処理からデジタル化から始まったといえる。
ビジネスが分散化し、ネットワーク化され、進化するための社会的な契約の基盤を構成する技術とアクティブなホーマットの進化が同期している。
こうしたいわば技術の文化遺伝子の進化の歴史は、第6篇辺りで触れたい。
4◇ クロス表で、ものごとやできごとを全て表現したい
いろいろな事象を、クロス表で表現したい。リアルファクトやバーチャルファクトの事象、ものごとを測定したり表現してデジタル化したデータ構造を考えてみよう。
4.1 データの構造
データとは記録し、保存し、編集し、配信し、再現できる記号である。いま、データがコンピュータで、こうしたい一連の処理が可能になり、そこから意味の抽出までもが可能になってきている。そのため、データが計算可能な構造としてどのような形式が有るかを整理したい。
・データの構造・・・リストデータ
一番簡単なデータの表現構造は、アイテムごとに箇条書きにしたリスト構造と言われるタイプである。
例えば、ワークショップでポストイットに張り出されたアイデアや、ブレーンストーミングの100本ノックで出された100個のアイデアリストや、レストランにランチメニュー等のデータである。
・データの構造・・・クロス表データ(行列データ、マトリックス)
例えば、言葉や文章から意味を採りだす場合では、テキストマイニングでは、各アイデアを表側に、これらが含むキーワードを表頭にとり、各アイデアが、それらのキーワードを含むか含まないかを、「1、0」でそれらのクロスポイントに埋めることでクロス構造のデータとなる。
技術の分野では、力と歪の関係や、電圧と連流の関係など。経済の分野では投入資源に対する産出資源の量や、政治の分野ではポリシーミックスに対する市民の満足度など枚挙にいとまがない。
・データの構造・・・入れ子データ
親アイテムに入れ子になった入れ子構造データがある。例えば、市町村アイテムの属性を示すデータは、各都道府県を親アイテムに入れ子になった入れ子構造データである。
・データの構造・・・ネットワークデータ
これらを全てカバーできるネットワーク構造等がある。例えば、各アイテムを結んでその結びつきの強さを数値で示すネットワーク構造データがある。例えば、山手線の30駅を結ぶ距離データは、30駅をアイテムとするネットワーク構造データとなる。
またもし、山手線の内回りと外回りを区別すると、方法性のあるネットワーク構造データとなる。例えば、新宿から外回り線に乗れば代々木は近いが、外回り線に乗れば、最も遠くなる。また、中央線も入れると、距離は複雑になるが、ネットワーク構造データでやはり、クロス表で整理できる。
・データの構造
こうした一見クロス表データ構造では扱えそうに無いデータでも、全て工夫すれば、ネットワーク構造データで表現でき、クロス表に表現できる。こうした具体的な例は、各編で紹介される。
そして、いま、”言葉と数字”の編集や表示機能等のコンピュータによる計算処理が始まっており、クロス表2.0世代に入ったといえる。
4.2 ものごとを理解するためのデータの構造
物事(ものごと)は、3項関係で表現できる.
テキストをクロス表で整理する前に、物事や出来事がどのように表現できるか考えてみよう。何かを説明したい時、主題とそのあり様や動きを説明することになる。
出来事は物事の変化する状態とすると、まず物事についての説明を考えよう。これは、物事が一つ一つ区別できることから始まる物事の認識の問題である。そして、出来事は物事の移り変わりであるので、その先で考えることにしよう。
注目する事象である主語を、ここではサブジェクトといい、そのアイテムが持つ説明語をここではアトリビュートといい、属性と呼ばれる。
あるSという事象は、その色Aや形Bや特徴Cや性質D等から説明され、区別される。こうした区別する要因が属性である。
そのため一番簡単な文章は、3つの要素から成り立っている。いわゆる主語+関係語+説明語である。従って、言葉をデータとして一番簡単に記述する形は、この3点の構造を使う。
文章における言葉は、連環し合いながら言葉の集合を作り、ネットワークを作っている。コミュニケーションのコンテキストを形成している。
言葉のネットワークから意味が生まれる。意味の共有から文脈が生まれる。意味は言葉のアイテム間の関係の中にあって理解できるが、コンピュータはそうは行かない。
コンピュータが理解できるように、データ形式を整理して上げる必要がある。
しかし、人間も、理解していることの全てを機械に直接伝えることは難しい。また、人間は、多くのアイテムから成り立つデータの全体の意味をすぐ理解するのは難しい。
実際の姿リアル・ファクトは、2項関係に落とし込んでしか捉え、整理し説明するのが、一番楽である。
さらに、2項を結んでその関係の性質を説明する第3の項が必要で、結局、3項関係となる。[2.10]
そこで、こうした3項関係をネットワークデータとして、整理することになる。
例えば、「鳥の肉は軽い」という簡単な命題を採り挙げてみよう。これは、人が外部を認識する時の原始命題と言われている。
原始命題:主語S⇒述語P+属性語A
というトリプルモデルの3体構造となっている。ヒトがヒトにあるものごとを指し示したとき、それは、仲間にとって意味のある事象の出現の発見を教える言葉では無かったのではなかろうか?
これをクロス表で整理すると、[図3.1]のようになる。

サブジェクト・アイテムは、「鳥の肉」であるが、これにいくつかの肉や食品をリストアップし、アトリビュートも、美味しさ等をリストアップすると、料理の会話が整理できる可能性がある。
実は、USでは、こうしたテキストを構造化して、オープンガバメントのオープンデータとして、政府が持っている公開を進めている。そこでは、各サブジェクトやアトリビュートやプレディクトまで、URLでリンクを貼ったトリプルを、RDFモデルとして、さらに深い、ダイナミックなコンピューテングが可能となる構造化し、その相互運用法の規格も研究を進めている。
4.3 クロス表で主体と属性とその結びつきをデータ化する
クロス表は、ヒトのように3つの部位からできている。
・表の側面(通常左側)に、ラベルをリストアップし、これを表側と呼ぶ。
・表の上部の表頭に、ラベルをリストアプして貼り付け、これを表頭と呼ぶ、
・この表側ラベルと表頭ラベルの関係する強さの度合いを数字で埋め、これを表体と呼ぶ。
この読本では、表体を連環度という。
以上のクロス表を構成する3要素のセットで、ものごとを数値実装したデータモデルが得られる。
連環度は、このクロス表データの、キーコンセプトで、結びつきが強い程大きな正の値である。
つまりあるサブジェクト・アイテムの特徴で、存在する理由や確かさや意味であるとも言える。
属性との結びつきの強さや結びつきの形である。
ヒトが、数値を理解するのは、リンゴやお菓子のような数えることができる計数値でその大きさの度合いは、指を折ることで、抽象的に示すことができる。
また歩き始めてつまずく石の大きさ、飛び越えられる川幅や目指すところまでの距離などの物理空間距離等の連続的計量値である。
また、意味の関係を示す、言葉と言葉の距離・・文章における位置や時間的関係や他の仲介する言葉との共起度ネットワーク上の距離等である。
簡単な例でサブジェクトとアトリビュートと連環度を考えよう。
下に、トランプカードが4人に配られた時のある人のカードセットの内容である。
[表3.1] のクロス表の表側は、カードの種別であり、表頭は種別の中の番号である。表の側面(通常左側)に、ラベルをリストアップし、これを表側と呼ぶ。
”表連環データ分析”では、表側はサブジェククトと呼び、表頭をアトリビュートと呼ぶ。表側の{♡、♢、♣、♠}は、4のサブジェクト・アイテムと呼び、{A,1,,,Q,K}は、の上部に、ラベルをリストアプして貼り付け、これを表頭と呼ぶ。
|
|
|
表頭 アトリビュート
|
||||||||||||
|
表側 サブジェクト
|
|
A
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
J
|
Q
|
K
|
|
♡
|
0
|
1
|
1
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
0
|
1
|
0
|
|
|
♢
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
1
|
|
|
♣
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
|
|
♠
|
0
|
0
|
0
|
0
|
1
|
0
|
1
|
0
|
0
|
0
|
1
|
0
|
0
|
|
[表 3.1]あるヒトに配られた13枚のトランプカードの例
また、表体の数字は、サブジェクト・アイテムとアトリビュート・アイテムとの結びつきの強さ、例えば類似度等を示す値で、連環度と呼ぶ。連環度は0以上の非負の値である。
ここでは、ある人の手にあれば”1”、なければ”0”を示している。
表体の数字のセットは、数学では行列(Matrix)と呼ばれる。この例では、4行13列の行列である。
1行目の♡の行は、{0110010010010}は、長さ13の行ベクトルまたは13次元の行ベクトルと呼ばれ、1列目の
|
0
|
|
0
|
|
1
|
|
0
|
は。長さ4の列ベクトル、または4次元のベクトルと呼ばれる。
列ベクトルと言わないのは。数学では、ベクトルと言えば列ベクトルが普通であるからである。
4.4 物事を言葉で表現し、データ化しクロス表で整理する
ものごとを言葉でデータ化する手順を考えよう。
まず、リアル・ファクトを、スタンスとスコープを決めてリアルファクト・データとして切り取り、その構成アイテムをリスト化しその関係を使ってファクト・データとしてモデル化する。次に、これをクロス表に整理して、数値実装モデルを得る。
これを、理解を共有し、いろいろな情況に対応するための検討をするために、操作(シミュレーション)が可能な、可視化できるモデルを得たい。
何かを説明したい時、主題とそのあり様や動きを説明する。そのため一番簡単な文章は、3つの要素から成り立っている。いわゆる主語+関係語+説明語である。従って、言葉をデータとして一番簡単に記述する形は、この3点の構造を使う。
もう少し別な例を考えてみよう。
”これ”は、”ペン”、”です”。
”あれ”は、”アップル”、”です”。
”それ”は、”アップル-ペン”、”です”
”ペン”は、”アップル”に”刺さっています”。
といった少し前に、トランプ一家にも受けた例である。
こうした一番単純な文章は、ものごとのあり様や成され方を示すデータとしての構造を持っている。
これは、クロス表の形に整理できる。表側をサブジェクト・アイテムと呼ぶことにする。サブジェクトはモノゴトの主体であり主語である。アトリビュートは、主語の状態やあり方を説明する属性であり、この両者を結びつけているのが、主語と属性の関係性を説明するプレディクトである。
|
|
アトリビュート
|
||||
|
a pen
|
an apple
|
an apple-pen
|
|||
|
サブジェクト
|
#1
|
This
|
is
|
|
|
|
#2
|
That
|
|
is
|
|
|
|
#3
|
a Pen
|
|
stabs
|
|
|
|
#4
|
It
|
|
|
is
|
|
[表3.2] クロス表展開形式データに整理
データの集まりは、個々のデータごとに、”サブジェクト+プレディクト+アトリビュート”という形で整理できる。
クロス表をサブジェクトのアイテムとアトリビュートのアイテムごとに展開してクロス展開表に整理できる。
クロス表の表側アイテムの集合をサブジェクトと呼び、表頭のアイテムの集合をアトリビュートと呼ぶことにする。表中の値は、"is",や"Is not"や"Stab"とテキストで記述されている。
サブジェクトとアトリビュートの各アイテムはテキストであるが、プレディクトもテキストである。
クロス表をサブジェクトとアトリビュートとの関係を計算できるように、プレディクトが数値になるように整理する必要がある。
|
|
アトリビュート
|
|
||||
|
a pen
|
an apple
|
stabs an apple
|
an apple-pen
|
|||
|
サブジェクト
|
#1
|
This
|
1
|
0
|
0
|
0
|
|
#2
|
That
|
0
|
1
|
0
|
0
|
|
|
#3
|
a Pen
|
0
|
0
|
1
|
0
|
|
|
#4
|
It
|
0
|
0
|
0
|
1
|
|
[表3.3] クロス表(数値)データモデル
さて、いよいよ、テキストデータを、コンピュータが可読なクロス表データとして数値実装モデル化する。
プレディクトとしての数値は、ここでは”連環度”と呼ぶ。連環度は、サブジェクトとアトリビュートの各アイテムの関係が強いほど大きな値となるよう数値とする。ただし、連環度は、非負(”0”以上)の値とする。
サブジェクト・アイテムとアトリビュート・アイテムのクロスポイントの部分に、それぞれのアイテム間の近さが大きいところに”1”、小さいところに”0”が入っている。
こうして、”個別データをクロス表として数値実装された元データ”を、”プロファイル・データ”とか”整然データ”等と呼ばれる。
最近は、単純集計やクロス集計のグラフを造って可視化することを持って、データ分析であるとする傾向がないでもないように見受けられる。
もちろん、そうした周辺情報をまず理解することは、極めて大切である。しかし、そこから読み取って、何らかの施策や意思決定をするのは、十分気を付ける必要がある。それは、サンプリングを含め、幾つかの要因の組合せ効果があり、結論が逆にでる危険があるからである。
個別のプロファイル・データの分布を確り理解する必要がある。
▼△▼△▼△▼△▼△▼△▼△▼△▼△▼△▼