序編 プロローグ
ビジネスはすべてイノベーションとなってくる
4章
イノベーションで事象の連環の形が切り替わる
いま、新型コロナで3つのソサエティのプレイヤが、その生き残りゲームを競い、生態系を組換え始めているように見える。
シチズン・ソサエティとビジネス・ソサエティが揺らいでいるが、最も挑戦を受けているのは国等のディクテータシップ機能のマネジメント・ソサエティであろう。
その与件たる環境資源コスモスとメディア資源コスモスの揺らぎは、どのようなリスクとイノベーションをもたらすのだろうか。
この4章では、この3つのソサエティの事象のつながり方のエコシステムを概観してみたい。
1◇分るということ・・・イノベーションの場と分布
1.1イノベーションの本質は如何にして「分る」か
モノゴトなど事象はすべて、何かが何かとつながり、何かがそこに流れる姿であるとする。
イノベーションは、事象のつながり方(Figure of ComBine)が、変わる現象といえよう。
これは、シュンペータの”イノベーションは新結合である”という命題にも通じるように思われる。
イノベーションは、役に立つ新しい知識、つまり役に立つ新しい情報としての技術を獲得することから始まる。
役に立つというコトの発見には、現状と、ありたい近未来と、それらをつなぐ橋との、3者の新しい出会いと結合が必要である。
そう仮置きすると、現状と出合ったときその本質を、良き未来をイメージしたときその本質を、まず理解したい。それらが理解できなければ、つなぐ橋を考えることもできず、またその橋に出合っても渡ることができない。
例えば、新型コロナとは、その本質とはいったい何だろうか?
そこで起こっているいろいろな事象について、メディアは連日報道している。が、そこでヒトは何を見、何を望み、何を感じ、どうしようとしているのだろうか?
この社会現象は、何かの流れを変え、何かを解消し、あるいは、何か新しい秩序に向けて、何か新しい形を造ろうとしているそのプロセスなのだろか?
”出会うあらゆる事物について、その「本質」を捉えようとするほとんど本能的とでもいっていいような内的性向が人間、誰にでもある。・・・われわれの日常的意識の働きそのものが、実は大抵の場合、様々な事象の「本質」認知の上に成り立っているのだ。
日常的意識、すなわち感覚、知覚、意志、欲望、思惟などからなるわれわれの表相意識の構造自体の中の最も基礎的な部分である。・・・これは西洋と東洋哲学でも共時的で共通の概念である”、と井筒俊彦はいう。[4.1]”意識と本質”
ヒトが事物に対し知りたいということ、それは事物の本質を知りたいということで、簡単に言えば、本質は、ヒトがある特徴的な事象や環境と対峙した時、感覚、知覚、意志、欲望等を表現する言葉が有るか無いかで、本質が分るかどうかということであろう。
ヒトが新型コロナという新しく出現した社会環境に対峙した時、この現実をどう理解したらよいのか。動揺を感じるのは、感覚、知覚、意志、欲望等を表現する言葉が見つからないからであろう。確かにCOVID-19と言う記号は命名した。しかし、その先、どのような言葉が、その後の社会に表出してくるのであろうか?
ここで、この読本のデータ分析に立ち返ろう。
この読本では、ファクトデータから意味のあるデータ、これを情報として取り出し、さらに役に立つ情報つまりこれを知識として蓄積することが目的であった。
さて、ある物事をテーマをサブジェクトとして採り挙げたとき、ヒトが意識するのは、その特性であろうか、それともその特性を特徴づける属性としてのアトリビュートであろうか? はたまた、その特性と属性をつなぐ形や度合いの強さであろうか?
社会環境の特徴的な事象の本質は、そのどの辺に有るのだろうか?
多くの従来のデータ分析法では、この3種を区別してその違いや関係を説明してこなかった。
ただ、クロス表データの形式を扱う”連環データ分析”では、既に述べたように表側アイテムと表頭アイテムと表体の連環度としてこの3の要素を区別する。
表側のラベルをサブジェクト・アイテムとし、表頭のラベルをアトリビュート・アイテムとしたとき、表体の数値はこれらをつなぐ強度の3の要素がそれである。
1.2イノベーションの対象としての事象は分布している
話を先に進める前に、イノベーションという現象を考えたとき、そのテーマとしてのサブジェクトを考える上で、この3要素の他に、もう一つ大切な要素がある。それは、イノベーションに関わる事象に関する母集団という考え方と、そのサイズに関することである。
いま、関心のあるテーマ、つまりサブジェクトには、サブジェクトを構成する複数のアイテムがある。これをこの読本では、サブジェクト・アイテムと呼んでいる。
従来のデータ分析法では、母集団という概念があって、いま想定したサブジェクトの全体を構成するサブジェクト・アイテムの分布を把握もしくは推定するというのが、この学問の最も大きな関心ごとであった。
それは、データ分析の目的が、如何に判断や診断をするか、その対策や処方を、如何に効果的な意思決定に結びつけるからであった。
このことは、対象とする母集団の範囲やサイズに関わる。
従来のデータ解析の中心課題は、無限多数のアイテムからなる母集団を想定し、それを如何に少ないサンプルで、その”不特定多数”の母集団の分布を如何に正確に推定するかであった。
もう一つの領域は、特性に効果的な要因を実験計画して、個々のサンプルの氏と素性が判る形にしたサブジェクト・アイテムを扱う問題で、サンプル自体がサブジェクトの構造や振る舞いの全体をカバーするいわば”特定少数”の母集団の問題であった(もっとも母数型実験計画法に限られたが)。
しかし、IoTの時代となり、いわば第3の領域が現れた。そこで扱う母集団は、あらゆるモノゴトに名前がついて無限に近いサブジェクト・アイテムが区別でき特定できるようになって、”特定多数”の母集団の問題を扱うケースが登場してきた。いわゆるビッグ・データ現象の1側面である。
「母集団」の概念は、問題の設定によっては、プロダクツの品種やサービスのジャンルや、業種・職種・業界や、動植物の種別等のカテゴリー、さらにコンセプトにまで拡張した適用が可能である。
では、分布を知るという意味を考えてみよう。
具体的に特定の個別な事象、例えば、医者が診ている一人の患者。この人が、果たしてコロナに感染しているかどうかという事象を採り挙げてみよう。
その特性を診断する場合は、n=1の個体に対決することになる。しかし、この時医者は、実は多くの患者に照らし、診断をしているのである。
医者が、来院する患者の全てを合せても、医者が経験を獲得できるのは、特定少数である。これは、どのような専門技術者であっても、マネジメントや営業マンであっても同様であろう。
ただ、医学という経験値を集合した専門知識によって、つまりその事象は該当する母集団のあれこれとの比較対照群から、そのケースのポジションを確かめることができるのである。
多くの場合、サブジェクトを構成するサブジェクト・アイテムの分布全体の形を知りたい場合と、ある特定のサブジェクト・アイテムが、分布のどの辺りに位置するかを知りたい場合等がある。
前者の場合、例えば、コロナに感染してから発症するまでの経過時間の分布や、感染してから治癒または死亡するまでの経過時間の分布等である。
後者の場合は、ある患者が、感染しているかどうか、あるいは感染してからどの位経過しているか等である。
この読本では、事象の本質に迫ろうとするテーマ、つまりそれをサブジェクトとしたとき、有限・無限の特定・不特定のサブジェクト・アイテムからなる母集団を対象とし、そこからの複数のサブジェクト・アイテムが抽出されたデータについての分析としよう。
あるデータが、想定している母集団やカテゴリーを代表しているかを常に意識することは絶対に必要である。
また、データの前処理についても、その観点からの用心深い注意が絶対に必要である。
1.3イノベーションという事象の特性と属性と連環度
イノベーションの対象の事象を、特性と属性と連環度から考える。
もう一度、サブジェクトの本質に迫る3要素の問題に立ち返ろう。つまり、分る対象としての特性と属性とそのつながりの形・強度である。
さて、特性が生死にかかわるような場合、特性と属性とどちらが中心的関心の要素となるだろうか?
ついサブジェクト・アイテムの特性に注目しがちかも知れないが、対応策や意思決定では、こうした特性に最も寄与する属性を探索するという、効果が最もある属性に注目せざるをえない。
また、その効果がどの程度あるかについてこそが問題となるだろう。新型コロナに対し、アビガンが決定的に効くか等である。
当たり前ながら、この簡単な例からも、注目すべき対象として、サブジェクト・アイテムと、アトリビュート・アイテムと、それらを結ぶ強さの度合:連環度は、いずれもがそうした事象の本質に関わっていることが判る。
つまり物事の本質は、3要素が一体である、と言うべきであろう。
ただ、なぜヒトは特性に拘りたがるのか、これには注意しなければならない。また、サブジェクト・アイテムとある属性との繋がり方が、各種いろいろある所に、または手を打ちやすく、業況共有をし易い属性変数への嗜好性にも原因がありそうである。また、特性に直接関係する効果的属性を探索し、確証するモデルを早く手に入れることを急いできたのではないか。
結局、ビジネスでは多くの場合、その特性を売上や利益等をKPIとし、外形的で形式的で計量でき、足し算引き算分解できるパフォーマンスの数値に頼ってそれに偏ってきた。
こうしてみると、実は、全く新しい社会環境の出現によって混乱、困惑する理由は、脳の経済学に支配され、外形的で形式的で計量できる、それで対処できると思い込んでいた”科学的マネジメント”に傾斜しがちゆえの脆弱性に有ったのではなかろうか?
1.4属性変数のデータタイプは5類型化できる
ある主題(subject)についてその個別事象(subject item)を理解するためには、その事象に関するある属性(attribute)についてその事象が持つ属性の情報量の多さを知る必要がある。
各属性は、その実現する数や量や色や形を具体的に、いろいろに顕現し実現する。そのため、属性変数と言われる。
そしてその実現する形態によって、変数タイプがある。さらにこうした属性の変数タイプには、情報量に大きな違いがある。
まず、あるサブジェクト・アイテムを説明する属性変数:アトリビュート・バリアブルは、大きく5のタイプに分けることができる。
1)ノミナル・データ
サブジェクトをあるテーマでのアンケート調査で、属性が、性別の男女や、地域名等であれば、ノミナル変数と言い、これらのアトリビュート・アイテムのラベルを例えば、男. 女を変数として表頭にとると、連環度のデータタイプには、属性の有無を[1or 0]で表現できる。これはいわば情報量が薄い軽いデータである。
コインをトスして[表、裏]は、バイ・ノミナルで、サイコロを振ったときの[1,2、、、6]は、マルチ・ノミナルである。テキストマイニングでどのキーワドを含むかは7万語位のマルチ・ノミナルとなる。バイ・ノミナルの出現頻度分布が2項分布(バイノミナル ディストリビューション)と言われる。テキストマイニングでは、ディレクレ分布と呼ぶ習慣があるが、これも多変量分布である。
2)オーディナル・データ
また、サブジェクトをあるファストフードのM個のブランドとして、アトリビュート変数を味の良さランクとすると、サブジェクト・アイテムが1位からM位までの順序数が入ることになる。これは、オーディナル変数と言われるノミナル変数よりも、少し厚めのディープなデータタイプとなる。
よくある、○○トップテン・ランキングは、日本人が大好きな話題である。もっともUSでは、車の顧客満足度をランニングし、そのトップテンだけを発表して、それが顧客に受けたため、大きなビジネスになったJ.Dパワーズのブランド調査が有名である。
またヒット曲チャートのランキングや、Googleのレコメンデーションの順位もオーディナルな属性データである。
3)ディスクリート・データ
また、数えられる離散数で表現できる例えば、ファストフードでも出店数や来客数などのデータである。これは、ディスクリート変数タイプと言われ、さらに細かく、ディープなデータタイプとなる。
目で見、触って、指を折り曲げて数えることができる一番古い数値である。
ただ、インド・アラビアが0という数値を発見し、使い方を発明したのは後のことであったが。
4)コンティニュアス・データ
また、さらに細かく、連続的なスケールで計測したコンティニュアス・バリュアブルと言われるデータタイプの変数がある。
度量衡は、国の礎、道幅やその長さ、納める穀物の大キサ、取引する貴重品の重さ等、比較はできるが、連続的数値の尺度は、言語と同様、みんなが使うことによって、標準価値が計測でき、分業で効率化できた。
ビジネスで言えば、売上高や再購入率や顧客層の地域的な広がりなどである。これは計数値よりもっとディープなデータタイプとなる。
5)パターン・データ
COVID-19では、感染者かどうかをPCR検査で診断をしているが、CTでもかなり診断ができる。レントゲン写真は一枚の写真であるが、CTは、いわば輪切りにした何枚もの写真で立体に診ている。PCRも遺伝子の特定のDNAの鎖の有無を調べているので、かなり厚めのデータではあるが、CTや抗体濃度等のpターンデータのバイオマーカも極めて情報量が多く強力である。
さらに、他に体温や血液中の酸素濃度や白血球の量等の数値の変化、さらには呼吸状態の動画等まで考えられる。さらにまた、患者の説明する自覚症状やその経緯等のテキストデータも、同一のサブジェクト・アイテムに紐づけられると非常に深いデータとなる。
こうして、粗く5種類の属性変数のデータタイプに分類した。
連続する量で計量したり、属性の色や形で表現したり、属性として仕草や動きや出す音等を伴った映像で表現したり、さらに臭いや触感などの感覚を再現できる仕組み等いろいろあるが、深い意味を持ったデジタル・データで表現できれば、情報量は大きくなる。
情報量が多くなるほど、診断の精度は上がる。診断の精度は、偽陽性(本当は感染しているが検出できない)や偽陰性(本当は感染していない)の確率である。
次に、属性の変数タイプと連環度のデータタイプの情報量の関係を、考えてみよう。
1.5 全てのデータタイプは連環度でノミナル化できる
実は、事象の属性の持つ情報量と、事象と属性との連環度のデータタイプ(Datatype of ComBine)とは、ある意味で同じ意味なのである。その理解がこの節の目的である。
上に述べた5類型の全てのデータタイプも、クロス表形式で、全てノミナル・データタイプの変数形式に変換できる。
それが、画像や映像や音像であれデジタル化されていれば、どのようなアトリビュート変量であっても、アトリビュート・アイテムとして、幾つかのセグメントに分けることで、連環度を[1,0]のノミナル変数に変換できるのである。
つまり、従来のデータ分析では、変数のデータタイプと、連環度の強さのデータタイプを分けて説明しなかったために、コンフュージョンを起こしていたのである。
ただ多くの場合、計量型アトリビュート変数を使いたい理由は、特性と要因の関係が非常に簡単なモデルが得られる可能性がある。簡単なモデルは、説明しやすいし、使い易い。
また、計量値属性と言っても、特性に対し必ずしも、比例関係の効果があるとは言えないが、両者の関係モデルを簡単にするためには、そうした仮定を置く方が便利であるという利点かあったからである。
しかし、実際コロナの例では、白血球の数や、体温が高い程感染度が高いという関係がどのような範囲で成り立っているか、限定的であろう。
その原因の一つは、離散数学と連続数学や離散統計と連続統計の専門や生い立ちの違いがあり、テキストも分れているという事情があった。
そのため、データの類型化型別のデータ解析技術を習得したり、ソフトを使い分けたりする必要があった。
むしろ、これらの属性値をある一定間隔でセグメントし、ノミナル変数に置き換え、隣りあったセグメント間をスムースに繋がるように、データを前処理する方が、遥かに合理的であろう。
画像データも映像データも音像データも同様に扱えることが望ましい。
また、テキストデータは、複数のキーワードを含んだ形で、いわばキーワードとの連環度で繋がったネットワークデータである。これらも、属性はノミナル変数であるが、属性変数の数が非常に多いが、すべてノミナル変数として扱うことができる。
連環データ分析では、こうしてノミナル変数に変換することをお奨めしている。(もちろんオーディナル変数や計数型変数や計量型変数でも、サブジェクト・アイテムとアトリビュート・アイテムをつなげる強度が大きい程大きな値となれば、そのまま処理できるが)
こうして、アトリビュート変数と、サブジェクトとアトリビュートを結ぶ連環度は、同等な意味であることが判る。
2◇特性要因図という事象の捉え方
2.1 特性要因を、連環データ分析の立場から考える
ヒトがある事象に直面したり、何か行動に移ろうとするとき、あるいは実践しようとするときは、個別具体なイメージを必要とする。
例えば、ある肉料理が出されたとき、それが何の動物かをしりたくなるであろう。その姿形や色ばかりでなく、臭いなどを観察するだろう。
それは、過去の体験に結びつくマルチモーダルなエピソードが要求されるからではないだろか?
ある製品やサービスを設計したい場合は、それを構成する全ての部品やサービス要素とその配列や接合法を決める必要がある。そしてそれらがユーザと使用されるプロセスで発揮する機能や性能や、魅能や使い勝手の使能等が要求される多様な価値を発揮するようにデザインしなくてはならない。[4.2]平林千春
つまり、設計という仕事はすべて、この世に初めての、個別具体的な、あらゆる多様な属性を、実在させることである。例え、どんなに個別性があっても、利用できる資源や情報や知識に限りがある限り、またヒトが理解できるものである限り、全く新しいものは実在できないが、それでもすべてを誰かが実装しなければ、物事が実在することはない。
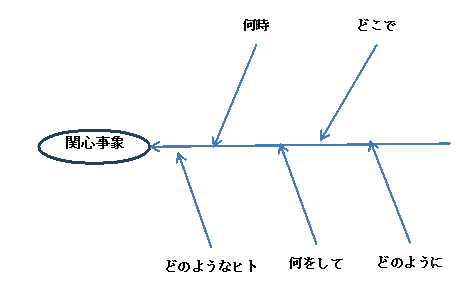
[図4.1] 特性要因図 Cause Effect Diagram
こうした特定の製品やサービスがもたらす結果と、その属性との関係は、特性要因図として表現することを石川馨が提案し、JISにも規定され使われてきた。[4.3]JIS1986
これは、ある結果を招来する原因系を調べたいために、衆知を集めて集合知を形成するコミュニケーションツールとして使われた。
石川が想定した特性は、製品等の良否等を決める原因を整理することであった。
例えば、シューハートの様に、工程の品質状態がアウトオブ・コントロールになったとき、品質を決める要因は、マテリアル、マン、メソッド、マシン等の4M'sであるとして、または、受け入れ検査でロットが不合格とまったとき、その原因を追究するため等に、衆知を集めて議論をするためのツール等に使われた。
こうした例では、特性は品質であるが、組織として大切にしたいKPI:キー・パフォーマンス・インディケータでも良いかも知れない。
また、英訳では要因と効果グラフ:cause-and-effect diagrams と呼んでいる。その目的は、特別な効果をもたらす要因:to identify potential factors causing an particular effectとしている。ただ、特性が何かは明確でない。
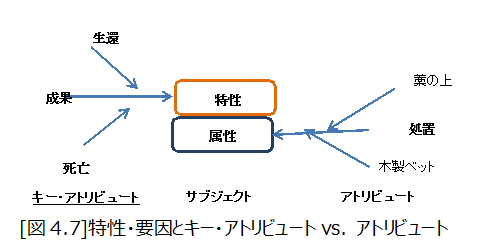
一方、属性の大切さを指摘したのは、クリミヤ戦争に参加したナイチンゲールで、そこから応用統計が始まったことは既に述べたが、彼女は、非常に多くある属性の中から、負傷兵の生死という特性に関わる要因として、ベットの種類という効果的な属性をピックアップしたのである。
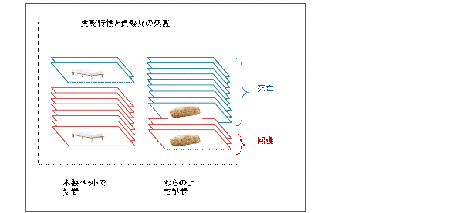
[図4.2]
彼女が使ったのは、特性をサブジェクト・アイテムの兵士の生死にかかわるものとし、そのアトリビュート(属性)も単独で、各アイテムを繋ぐ連環データタイプは、最も簡単なノミナル値、それも2値のデータタイプであった。そのアトリビュートがそのアイテムのベットの種類を[1or 0]で示す最も簡単な連環度であった。
例えば、戦場の負傷兵の生死という特性が、藁の上か木製のベットであるとしよう。カードに兵士の名前を書き、そこに処置を書いて仕訳をして図のように積上げたとしよう。
生死という特性とベットの処置が強く関係することが明らかになった。それまでわらの上で処置されていた兵士の死亡率は木製のベットに比べ圧倒的に高かったのである。ナイチンゲールが応用統計学の母と言われるようになった所以である。
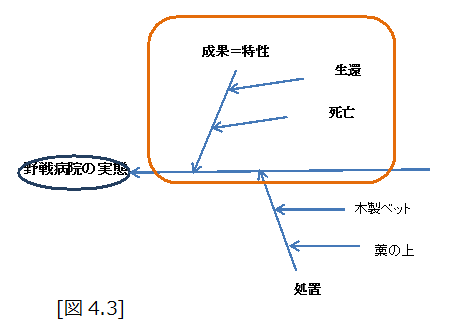
連環データ分析では、関心の事象をサブジェクトとし、その属性をアトリビュートとしている。特性要因図で定義し、取集したデータをクロス表として整理すると、表側に複数のサブジェクト・アイテムを採ったデータとなり、これは、プロフィールデータと呼ばれている。[4.4]宮川
この例では、特性とは何になるのだろうか?野戦病院に運び込まれた兵士の処置の成果の生死であるとする。
これを、連環データ分析の立場から、サブジェクトを兵士に対する処置としたとき、サブジェクト・アイテムは、処置を受けた個々の兵士となる。
そして、アトリビュートは、結果の生死と、処置としてのベットの種類となる。つまり、通常は、アトリビュートの内、重要な成果であるアトリビュートを特性と呼んだり、KPIと呼んだりしているように思われる。
ただ、それには、ヒトが気にしたがる成果とその貢献度や、結果とその原因の探索という傾向が有るからである。そうした事前の姿勢が、得られる結果にある種の歪をもたらす傾向は否定できない。
あくまで、個々のサブジェクト・アイテムとそれに付随するアトリビュートの各アイテムは、対等に、平等に扱う必要がある。
もし、特性やKPIを中心に検討したのであれば、これをキー・(パフォーマンス)・アトリビュート:KPAと呼ぶことにしよう。
2.2サブジェクトとキー・アトリビュートという特性
こう考えると、特性もまた、アトリビュートの一つとなる。そして、アトリビュートは、情報量で5段階のデータタイプがあったが、特性にも5段階の変数が有っても良いということになる。
例えば、ナイチンゲールの野戦病院の戦士の例では、キー・アトリビュートは、生死の2値のノミナル変数であり、その説明用のアトリビュートは、別途の2種のノミナル変数という最も簡単なデータ構成例となる。
この極めて簡単な層別というデータ構成例での成果のインパクトは、凄いモノであった。
ペストは、14世紀にヨウロッパの1/3の人口を死亡させ、キリスト教の権威を失墜させ、ギリシャやペルシャの科学や哲学に目覚めさせ、ルネッサンスを花開かせ近代国家へのトリガーとなったとの説がある。ナイチンゲールの層別の発明は、直ぐにスツールの細菌の発見に繋がり、その約500年後の北里柴三郎のペスト菌の発見にまで貢献したのである。
このインパクトは、2値の事前処置という属性のノミナル変数に対し、生死というキー・アトリビュートの成果属性のノミナル変数の分布が際立って対比した形となったからである。
2.3 単独なサブジェクトとキー・アトリビュートの分布
サブジェクトの本質を知るということは、サブジェクト・アイテムが母集団からのサンプルであるとき、そのアトリビュートの分布の形態やその構造を知ることや、あるサブジェクト・アイテムが、その分布の粗密構造やその分布におけるポジションを知ることである。
ただ、その構成アイテムの個々の属性をすべて記録したいわゆる”プロファイル・データ”は大切であるが、その全て個々のデータが直接、元データのまま利用できる訳ではない。
サブジェクトの属性を多くカバーして集めたとし、その個々の全てを理解したとしてもその個体は、どの集団のどこに位置付けられるか、どのカテゴリーにどの程度帰属するのかの理解がきわめて重要だからである。
つまり、いくら具体的な個の事象と言えども、絶海の孤島であるということでは理解できない。どこかに帰属すること、帰属の構造の特性こそが、その個性の故なのである。こうしたことを、次にもう少し、考えてみよう。
これまで複数の属性変数の大切さと情報量の豊富な連環データタイプの重要性であったが、それが意味を持つのは、サブジェクト(主題)の対象とするサブジェクト・アイテムの分布の構造と分布状態こそが重要なのである。
その共通する性質や、その性質のバラツキ方や、また場合によっては、そこから外れたケースを知ること等は、全て分布に構造に関わることなのである。
1)特性値がノミナルでアトリビュートが計量変数の場合
アリストテレスの実践的叡智であるフロネーシスの3段階論法は、まず実践知と他の知との違いを機能論から論理的に説明し、具体的な3段階論法の例を挙げている
命題A:”軽い肉は、健康に良い”
命題B:”鶏肉は、軽い肉である”
命題C:よって、”鶏肉を食べる”。
人に教える方法(学問)として、①前もって知られていることがらから出発し、②基本的命題や普遍性へ帰納する帰納推論(Induction)、そして③もろもろの普遍的なことがらから出発して選択命題を導き論証する演繹推論(Deduction)、さらに、これらから④実践的個別命題に導く仮説推論(Abduction)などに及んでいるとされる[4.5]紺野。
ただ、命題A:”軽い肉は、健康に良い”は、どの程度正しいかは、データによって帰納的に実証が必要である。
確かに国立がん研究センタがEuropean Heart Journal 2013年ジャーナルに発表した論文でも、「飽和脂肪酸を食べる量が多いグループで心筋梗塞のリスクが上昇」との報告があり、アリストテレスの前提は正しい(脳溢血は逆の効果もある)。
また同様に、命題B:”鶏肉は、軽い肉である”もデータ帰納論的に実証が必要である。いま、鶏肉が下図の横軸のどこに位置するかという問題である。
この時、特性は肉が重いか軽いかであるが、要因は重さを示す飽和脂肪酸であり、計量値である。肉の種類についてデータをとり、鶏の肉が重いか軽いかを判断し、軽い肉に分類している。これも現代の医学の観点からも妥当であろう。
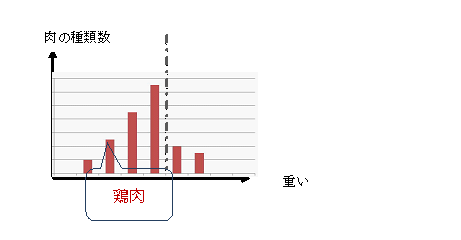
[図4.4]
こうした判断には、データが大切であるが、例えば、判断の誤りには、第1種と第2種の2つのタイプがある、コロナウイルスで有名になった偽陽性と偽陰性の誤りである。
2)特性値がノミナルで、アトリビュートが計量変数の場合と計数型変数の場合の比較
いま、ある部品のロットが与えられて、これを受け入れても良いかの判断が求められているとしよう。
このとき、特性は、そのロットに含まれる不良品の%で、不良品かどうかの基準は、その部品に含まれるある成分が25.0以上であるとする。
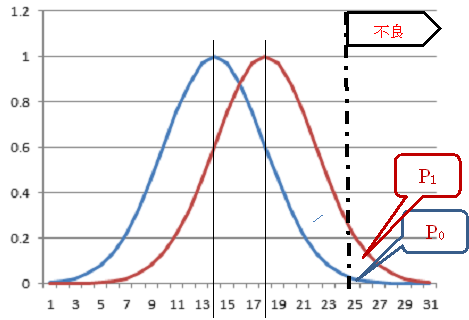
[図4.5]
図3.2は、横軸にある成分の量をとり、ロットの部品に含まれるその成分の分布を示している受け入れて良いロットの不良率をP0,拒否したいロットの不良率をP1とする。
不良率P0のロットは95%以上合格とし、不良率P1のロットの合格率は、10%以下としたい。
このとき、ロットからランダムにサンプルとしてn個の部品を抽出して検査をする。
この場合、サブジェクト・アイテムは、母集団N個からサンプルn個を抽出して、アトリビュートを調べることになる。
もし、アトリビュートとして、部品に含まれる成分を計量値として計測するか、単に部品の良否の2値のノミナル値として計測するかである。
JIS-Zでは、こうした基準型と言われる計数型と計量型の抜取検査表を用意している。
その結果のある例では、計数型では、400個のサンプルが必要であるが、計量型では、67個で良いことが判る。[4.3]
つまり、計量型の情報量は約6倍あると言える。
[図4.6]
この様に、ロットの特性をロットの品質としたときでも、ロット全体の分布を気にするか、不良率を気にするかで、データ構成は変わってくる。
あるサブジェクト・アイテムの部品が、このp0 のロットに入っているかp1のロットに入っているかで、合格は不合格かに分れるのである。
この[図4.6]では、p0 とp1の距離は大きく感じるかも知れないが、[図4.5]での計量値の平均値の差は大きくない場合がある。
許容できる限界リスク規準を、管理している業界は、未だ少ない。国際航空業界と、国際金融委員会位ではなかろうか?
ところで、知りたい対象としての物事の集まりは、データ分析では、母集団と呼ばれる。母集団をJISでは、調査、研究の対象となる特性をもつ全てのものの集団、としている。[4.4]
ここでは、あるテーマのサブジェクトを取り上げ、その全体性の理解をするということを考えてみよう。
この問題を、自我とは別に存在するものとしての対象として理解しようとしたいわば、西欧文明の基礎ともいうべき科学論を打立てたデカルトであろう。その根底には、全体を分解してその各部分を理解し、それを組み立て全体に戻して初めて理解に達することができるという近代の西欧文明を支配してきた科学的思想があった。
これは、近代の科学マネジメント論としても、問題や課題をMECE:”Mutually Exclusive, Collectively Exhaustive”に分解してコントロールしようとする考え方にも引き継がれている。
確かに、全体をうまく分けられれば、分かったことに近づけることは確かである。分かるという言葉は、まさに分けるということでもある。
前節では、実践したり、デザインしたり、対応するためには、個別で多くの属性を理解する必要があった。ただ、それらの個別性や具体性は、所詮、あるサブジェクトの集合における位置づけから来る意味であることであった。
そもそも、統計学は、あるサブジェクトを構成するサブジェクト・アイテムの属性値が計量変数である場合に、その集合が正規分布をするとい問題を中心に扱って来た。
多くのサブジェクト・アイテムは、ランダムな要因効果が独立に足し算される構造である場合は、正規分布となる。
あるテーマで問題にしている対象が、ある集団やあるカテゴリーである場合、その全体を一つ一つ数え上げてリストアップするのではなく、関心の特性の属性の分布として整理し理解することで済む場合がある。
特に、対象とする集団のサイズが大きいとき、そのサンプルをランダムに採って、その分布を調べて、対象とする集団やカテゴリーの分布を推定するのが便利である。
たとえば、新型コロナの感染者のような特性の属性変数が2値の[1 or 0]の場合では、関東地方の感染者の分布は、600人をCPSで検査すれば、1,500万人のうち何%が罹っているかは、+-4%の精度で推定が可能である。
もし、マスクでも少しは罹るリスクを軽減するなら、致死率が異なる年代別に層別し300人づつ、計2,400人を各県でランダムに調べ、そこに重点的にマスクを配布することで、一定の予算でも社会的余剰を最適に近い政策が可能である。
こうした効果的なサンプリングは、品質管理のデミングが開発した層別サンプリング方が有効な手段である。
やみくもに、北海道にマスクを送ったり、全国一律に学級閉鎖をしたりしないで、地域や、年齢や、職種や業種や、時間帯等の行動属性のデータが大切である。層化多段階サンプリング法等である。
コロナのPCR検査が日本で徹底的に忌避されたが、データ分析の専門家や病理学の医者が絶対的に不足しているという技術知識インフラの欠如があったことは反省されなければならない。
流行の速度や程度は、潜伏期間や施策の遅れの時間と正比例する。施策の遅れは、データの遅れや情報の隠ぺいに寄って社会的コストを遅れ時間に比例する以上に増幅させる。
いわゆる鞭を手元で少し振ると先では凄く震えるブルウイップ効果と同じ現象で、エクセルで簡単にシミュレーションできる。
潜伏期間属性は、多くの要因が関係するが、計量値ではあるが正規分ではなく、ワイブル分布を当てはめるのが妥当であろう。コロナの場合、潜伏期間の最頻値が7日位とされていあるが、そうすると隔離期間は2週間ではなく、3週間くらいが妥当であろう。形状パラメータを2とするワイブル分布は、長く尾を引くからである。
正規分布は、要因の効果が独立で加法性があれば出現するが、リングがつながった鎖の一番弱いところが切れるような信頼性等の分布では指数分布が表れる。また、システム稼働時の初期故障や、偶発故障や、劣化する老化寿命等では、形状母数が異なったワイブル分布が良いだろう。
正規分布とワイブル分布は、分布のセンター的なパラメータと広がり方の形を示す形状パラメータの2つを持っている。こうした分布のパラメータを知ることや、それもいろいろな属性よって、パラメータがどのように変わるかを知ることは、いろいろな事象の起き方を推定したり、意思決定をする上で、重要である。
ところで、実際の抜取検査では、ある計量値属性だけを調べることは少ない。部品でも傷や外見等を含めて、いろいろな属性を多重に計測する。そして、重欠陥があれば、たとえ1つでもロットアウトとする。
2.4特性要因図はマインドマップとなった
特性要因図は進化した。
マインドマップは、頭の中にあるアイディアや思考を視覚化する手法のひとつとして、トニー・ブザン氏によって考案された。
中央に発想のもとになるセントラルイメージを描き、そこから枝分かれのように思いつくことをどんどん膨らませていき、さらにその枝(ブランチ)から枝分かれするブランチを思いつくままに伸ばしていくという直感的な方法でアイディアを視覚化しながら、連想し広げて行ける。
特性要因図があるテーマから太い1本の幹を書き、そこから枝や小枝を出して行くのに比べ、マインドマップは、中心から何本でも幹を放射線状に出して思考を広げていく。
KJ法は、順序やつながり等を考えずランダムに発想して行き、後からこれをまとめて行くのに対し、ある中心的なテーマを決め、このように発想を広げていくことを放射思考と言っている。
連環データ分析では、サブジェクトは幾つかのサブジェクト・アイテムから成り、それを説明するアトリビュート変数があり、それらの多くが、ノミナル変数でも良かった。そして特性要因図でいう特性もまたキーとなるアトリビュートで、要因もアトリビュートであるとした。
特性自身が多くの幹を持つ問題では、特性要因図は、マインドマップに拡大される。マインドマップ流に、特性要因図を表現すれば、[図2.3]のようになろう
2.5特性要因図とマインドマップのデータ構成
連環データ分析に対する特性要因図とマインドマップのデータ構成へのデータの入力形式を考える。
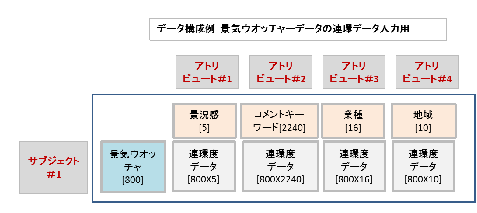
例えば、内閣府が毎月街角の景気ウオッチャーとして発表しているデータがある。
これは、所費の現場の業種を地域別に全国約800人から、景気動向を良くなった、やや良くなった、変わらない、やや悪くなった、悪くなったの、5段階で答えている。
これを、特性要因図として表わしたのもが[図2.4]である。
サブジェクトは、景気ウオッチャーで、サブジェクト・アイテムは800人である。
アトリビュートは、景気動向、その説明文に含まれるキーワード、業種、地域の4種である。それぞれアイテム数は、5個、2,240語、16種、10地域である。
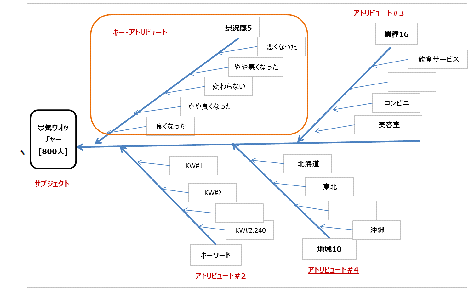
[図4.8]
特性は、景気動向でこれをキー・アトリビュートとした。
こうして整理したデータを、800のサブジェクト・アイテムと、4のアトリビュートの各アイテムと結びつきの強さの連環度を入れたクロス表データの構成法を[図4.9]に示す。
景気ウオッチャーの毎月800人をサブジェクト・アイテムとして、4個のアトリビュートがそれを共有し、4枚のクロス表となっている。クロス表を連環データ分析では、アイランドと呼んでいる。
景況感アイランドは、[800X5]の連環度の800行5列の行列で、コメント・キーワード・アイランドは[800X2,240]、業種アイランドは、[800X16]、地域アイランドは[800X10]の行列となっている。
これが連環データ分析の入力データ構成である。
この800次元の5+2240+16+10の計2、271本のベクトルを、連環データ分析では、コンピュータが、2~数次元に情報圧縮し、連環データマップを構成することになる。
[図4.9]
この多重な属性問題は、次節に譲る。
A※V※A※A※V※A※ コラム ※V※A※A※V※A※
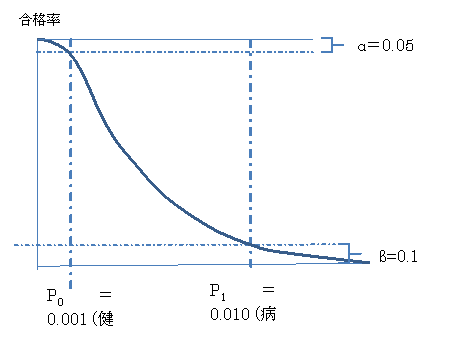
規準型抜取検査の理論はUSのコロンビア大のSRGroupであったが、国家規格として採用したのは、日本だけであった。
USのMIL規格は生産者危険を重視しP0のような<良いロットが落とされる危険をα=0.05に固定し、消費者危険のP1のような悪いロットが合格になる危険をβを野放しとした。欧州のピリップスは、両者の中間の合否がちょうど50%となる不良率をコントロールポイントP1/2とした。
これには、USでは良い成績を上げれば厚遇し、もし悪い製品を収めれば自己責任で罰せられる等、それぞれ、社会的文化的な背景があるが、規準型方式は、優れていた。
特に、民生用産業に舵を切った日本では、消費者危険を明確にすることは、時宜に適っていた。
P1は、LTPD(Lot Tolerance Percent Defective=ロット許容限界不良率)と呼ばれ、消費者が受けいれることができるぎりぎりの不良率の限界ということである。
昨今、統計的仮説検定を使った悪質な論説が目立つ。
例えば、「今までと変わったとは言えない。よって安全でないとは言えない。」の類である。
2000年ころ、狭山市のごみ焼却場の近くに住んでいる主婦とやや離れた所に住んでいる主婦の母乳に含まれているPCBの量に「有意差なし、よって問題ない」との厚労省の見解を大きな見出しで挙げたことがあった。技術ジャーナリストが日本から居なくなったのは、1985年頃からだったが、これは厚労省の間違いだったのか、日経新聞の間違い記事だったのか不明であるが、ちょうど、実践女子短大の教材とさせて頂き、その誤りの理由を単位認定に使わせて頂いた。
もちろん、その後、ゴミの焼却炉のPCB問題のための温度管理は、厳しく規制されることになった。
2011年、3.11から、多くの学者が低線量被爆の問題で、論文を発表されているが、残念ながら、LTPDの観点からのデータで安全性に言及したものを見たことが無い。
安全を陰に陽に指示し主張しているほとんどの論文は、有意差検定を意図的かどうかは別にして、「不安を煽って、風評被害を起こさないこと」に注意を払っているような、同調圧力に弱い”科学的論文”が多いように思われる。
最近、ノーベル賞クラスの論文や最もインパクトファクターが大きいと言われるNatureのような一流ジャーナルでも、有意差検定やP-値を使った論文は掲載しないとする傾向が広まっているが、日本では逆で、その形式さえ採っていれば通す査読者が多い。
A※V※A※A※V※A※ コラム ※V※A※A※V※A※
3◇発展する特性要因図とデータ分析
3.1プロファイルデータとプロファイリング
前節までは、単独のサブジェクトと単独のアトリビュートとの簡単な関係を、分布する状態として説明した。
どんな事象であっても、実在する事象、事実はすべて、背景や経緯やプロセス等いわば無数のアトリビュートを備えている。
本節では、単独のサブジェクトが複数の多くのアトリビュート共有しているケースに話を進めたい。
統計学では多変量解析と言われてきた分野である。
これは、プロファイルデータとして、サブジェクト・アイテムを表側にとり、表頭に複数のアトリビュートを取り、表体にその該当度で埋めたクロス表形式に整理したものである。
連環データ分析では、複数個のアトリビュートの数だけ、クロス表を別々に用意する。従来の多変量解析では、基本的には1枚のクロス表しか扱っていない。
このモチベーションは、多重の属性問題を如何に扱うかに起因する。
例えば、犯人を割り出すには、プロファイリングという手法が使われるが、このプロファイリングは、「1888年にイギリスで連続発生した猟奇殺人事件切り裂きジャック事件から始まったロンドンヤード(警視庁)が有名である。犯人像はいくつもの属性か探られて行ったが結局迷宮入りとなった。
被害者は、18人のケースがそれと疑われた。
事件のプロファイル(特徴・横顔)は、事件の属性として、ターゲトが中年の売春婦で、手口がナイフ等の切り裂きで、地域や時期が限られていたこと等であった。
しかし犯人のプロフィールは、目撃者の少なく被害者が全て死亡しており、明確でなく、犯人が新聞社に犯行の手紙まで送ってきたりしていたが、あまりにも手掛りがつかめず、警察官ではないかとまで言われたが、結局迷宮入りとなった。
シャーロック・ホームズで知られるアーサー・コナン・ドイルは、事件を扱った小説も発表していないが、切り裂きジャックの正体は「女装した男性」と推理していたと言われる。
例えば、クルーズ船に乗り合わせた3,700人の、性別や年齢、船に乗ってからの日々の行動記録等を分析することで、何時、どこで、何をどのように行動していたかを、プロファイルデータとして整理できる。
そして、発症したかのサブジェクト特性に対し、そのアトリビュート要因として表現することができる。こらは、社会にとって貴重な知見となるデータである。
また、1800年代の切り裂きジャックが、2020年3月の上海で起きたとすれば、上海の市民の行動ログ(行動履歴)データから、何時、どこで手紙を出し(3通の犯行についての新聞社あて)たり、事件現場の近くを歩いていた、どのような背丈や格好の人物で、その体温の変化や移動速度利用した交通機関や駅や、スマホの買い物履歴までのデータが分るであろう。
現に同年3月には、上海市では、街角のカメラで顔や体温が測定され、個人別にコロナの感染度合いまでもが、本人や当人が入ろうとするコンビニの入り口でも分って拒否できるようスマホのQRページデータとして提供されているとの報道があった。
こうなると、シャーロック・ホームでなくても、犯人を特定することは簡単である。
これは、たとえ2値の軽いノミナルなアトリビュートであっても、非常に多くの属性を持ったいわばワイドなデータなら、貴重な意味を持った情報が得られるからである。たとえ2値の匿名の[Yes, No]データであっても、多くの変数をあるIDに突合で切れば、個人名まで割り出すことが可能となる。
むかし、20回の質問で正解を当てる、20の扉というクイズ番組があった。
この様に、ある事象に関する全ての属性を記述できれば、かぎりなくその実体に切迫することができよう。
こうした単純だが大量なノミナル変数をもつデータは、テキスト解析のケースでも現れる。文章に含まれるキーワードは、数千に及ぶこともあるからである。その場合は、[図4.2]の横の区切は、ナイチンゲールでは木製ベットと藁ベットの2であったが、数千に区切る必要がある。
これはデータ解析としては、数千次元のデータとなる。
また例えば、テキスト分析のように、キーワードの数の出現頻度分布が必要であれば、キーワードの数だけの、多項分布となるし、質問項目が多いアンケート調査などの場合は、そのまま、分布状態を理解することは困難である。
また、属性変数が単独でも時系列のようなつながりを持った属性は、重要である。
たとえば、コロナ問題のクルーズ船の3,700人の行動ログ解析をする場合を考えよう。
この3,700人をサブジェクト・アイテムとするリファレンスデータで、30分ごとの3週間の行動を追うとすると、24時間X3X14=1,000のセグメントに横軸を区切る必要がある。
つまり時系列属性を持ったデータのような時間でリンクされたデータは、因果関係を見つけるには、有効である。
いま、電力会社やガス会社や石油会社などが、電力の小売り産業で、まさにゲームを始めているが、この業界では、30分毎の消費電力を計測して、家庭の電力消費行動ログを集めている。たとえば、夜中の2時に急に電気を使うようになったとすれば、その原因は、「赤ちゃんが生まれたのではないか?」という仮説から、新しいビジネスチャンスに結び付く可能性がある。
また、WEBにコマーシャル料を抜かれたテレビ業界でも、インターネットに接続したいわゆる“スマートテレビ”の視聴行動データを追いかけ始めている。スマートテレビは、関東圏だけでも数百万台あり、これでは、1分刻みで、どのチャンネルを見ていたかが分る。従ってお好みの番組や、曜日ごとの1分刻みの生活スタイルまで、知ることができている。
この場合、月の上中下旬や週の曜日や季節性もあるので、年間通じて調べると、365日X24時間X60分=50万次元を超えるプロファイルデータとなる。
こうした時間のリンク属性を持ったデータは、WEBや、家庭に張り込んできたスマート・スピーカや、スマフォのデータ、そして数年以上前から全ての自動車に実装されたスマートデバイスに至るまで、リンクが広がっている。
このような時系列属性を持ったデータは、因果関係の解明だけでなく、予測問題の領域に関係する。因果関係の推測や予測問題は、意思決定に有効である。
ただ、意思決定には、こうした多重属性を持ったサブジェクトアイテムの母集団やカテゴリの分布をどのように理解し分かるかがポイントとなる。
基本的には、こうした多様な多属性を持った個別事象のディープ・データを扱う多変量データ分析といわれた分野が大事である。この読本では、第1編以降、それに集中する。
3.2特性要因図からQFDへ、さらにKANOモデルへ
特性要因図のさらなる発展例は、赤尾洋二が提唱した品質機能展開(QFD:Quality Function Deployment)と言ってもよいであろう。[4.6]赤尾
このQは、顧客の要求仕様で、通常はテキストで記述された複数の項目からなり、それを満たす技術的機能要素も当然複数からなり、それらを結ぶ連環度データから構成されることになる。
このアプローチは、ハード製品やシステムデザインだけでなく、ブックセンターやEコマースサイト等の設計にも世界的に広く使われている。
こうした要求サブジェクトを、さらに太い枝として、いわゆるKano-Modelといわれる狩野紀昭が開発した品質の属性を評価する方針で括る問題は、マイクロソフト等がパッケージ化しているが、この読本では、第3編で扱う。
さらに、サブジェクト・アイテム同士がクロスする問題は、デザイン問題の本質に接近する問題である。これらも第3編で採り上げたい。
たとえば、患者と薬と間にいる医者のマッチングであり、たとえば求職する学生と求人する企業とその間にいる大学等の、相手を探しあう2のグループとその間を取り持つメディエイターとの3群マッチング問題である。
これも、大きなイノベーション領域とでもいえるきわめて重要な領域であろう。これも第3編で扱いたい。
3.3特性要因図はオントロジーとなった
インターネットやデジタル化とネットワーク化や知識化技術が突然現れた1995年頃になると、アマゾン等のEC:エレクトロニック・コマースが登場し、オントロジーというICT分野も研究されるようになった。
これもある意味、特性要因図がISOにも定義され、広く世界に使われるようになったこととも関係しているように思われる。
オントロジーは、ある特定の存在物を説明するために、その属性を階層構造で説明しようとしたものである。
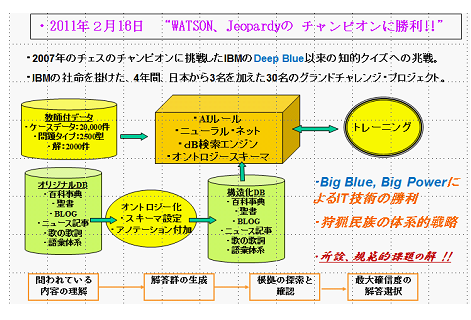
オントロジーが注目されたのは、IBMのワトソンというAIが、クイズJeopardyのチャンピオンを2011年に破ったことであった。
このJeopardyは、大学生等に人気のソニーのクイズ専門のテレビチャンネルで、チャンピオンも大学生だった。
例えば、「イスラエルのダヤン、それが身に着けている器具は何か?」と言ったクイズで、2人が早押しで正解を競って勝ち抜く番組である。答えは、「黒い眼帯」で、ダヤンがイスラエルの片目の将軍であることを理解できなければ、正解に辿り着けない。
ソニーは、コンピュータに負けて人気が落ちるのを気にして、AIがロボットの手でボタンをヒトと同じように押すことまで主張した。
[図4.10]
IBMは、百科事典、聖書、ブログ、ニュース記事、歌の歌詞から語彙体系までデジタル化したデータベースを構築し、これを人力でオントロジー化し構造化したデータベースを構築した。
この人気番組は2万位のエピソードがあり、その正解があった。[4.7]IBM
IBMは、3名の日本人を含む30名で4年間の社名を掛けたプロジェクトだったという。AIのルールを、教師ありデータで鍛え、3台のスパコンを使い、得意領域をそれらが役割分担したという。結果は、IBMが勝利した。その成果を使って、IBMはAIによるサービスを展開している。
これはまさに、ビッグ・ブルー(IBM)による、人海戦術のビッグ・パワーによるの勝利であった。
その後、USのオバマ大統領は、オープン・ガバメントによるオープン・データを宣言し、政府が持っているデータを、オントロジー化して公開するよう指令を発した。
同時に、相互運用可能なRDFモデル等のデータ構造の標準化の研究開発も複数の機関が並行して進めることも指令した。そしてその効果は、医療関係だけでも、何兆円もの成果を挙げられると期待している。
ただ、オントロジーとして表現されるデータには、連環度として4つの弱点があり、それらをカバーしなくてはならないと日本の産官連携プロジェクトが、1995年に指摘している:
1)連環度が出現頻度が意味をもつこの表現ができない
2)どの属性に帰属するかを背反にする必要がある
3)連環度にファジーな値が扱えない
4)アトリビュート間ではリンクが許されない
5)サブジェクトとアトリビューとの連環度は方向性を持ちこめないことなどである。
こうした連環度が様々なリンク機能でネットワークする問題は、今まさに発展途上にあるといえよう。
これらの問題は、第1編、第2編、第3編で、連環データ分析の新しい応用法として具体例をまじえて採り上げる。
さて、特性要因図と同じようなアイデを整理する方法が発達してきたが、改めて、特性とは何だろうか。
ある意味で、成果であったり、KPIに代表される指標であったり、特別な属性であったり、あるいはテーマであったりしていた。
しかし、クロス表の形で表現できる3種の要素は、サブジェクトアイテムの分布と、それらのアトリビュート・アイテムの分布との結びつき方が示す特徴の何かではないだろか?
そこで、この読本では、特性とは、主題を担う個々の事象の特徴、もっと言えば、個々の事象の集団としてのサブジェクトの本質または、本源的性質:Nature として措置したいが如何であろうか。
例えば、新型コロナの特性と要因を議論するとすれば、その本質、その特徴、その本源的性質を議論したいということである。
3.4因果関係と相関関係
特性要因図が当初、特性に関する原因と訳されたように、ヒトは何か原因を探索したくなる性向を持っている。
そのためか、ビッグデータが得られるようになり、事後データからそれを推定できるのではないかとする因果関係論が、活発になっている。[4.8]清水昌平
例えば、科学者や裁判官やメディアは、因果関係や犯人や責任者等を特定をするいわば社会的業務を担ってきたし、経済学者は、政策と成果の因果関係を議論する傾向がある。
応用統計学では、実験に先立って要因の効果が交絡しないように配慮する実験計画法がその重要な分野であった。
しかし、事後データからそれを推定することは、結構困難である。逆に、実際の問題では、たとえ因果関係が判らなくても、対応策、それも有効な対策が求められるケースが多い。
特に、科学的な原因追究よりも、技術的ま対応策を急ぐべき特異事象が多発している。異常気象やコロナのような、VUCA( Volatility変動性、Uncertainty不確実性、Complexity複雑性、Ambiguity曖昧背性)等と呼ばれている現状もある。
また、効果的な対応策見つかってのち、原因がわかることも多い。それは、技術が先行し、科学が後追いで説明する場合が多くみられるように、技術には社会が豊かになるためというモチベーションや心のエネルギーの駆動が有るからであろう。
つまり、データサイエンスと言うより、データエンジニアリングとでも言うべき立場をとりたい。
それに伴い、多数の属性変数間の関係性や相関性がクローズアップされてくる。また属性変数間の事前の方向性をもって探索する因果関係よりも、変数間の関係を平等に見る相関関係を大切にしたいのである。
3.5分析法のトレンドを概観する
こうしたアトリビュート変数が増えるトレンドに応える形で、フランスでが対応分析、日本では数量化3類、カナダでは双対尺度法、米国ではHomogeneity analysis, オランダではGifi-System等の開発が進んできてはいた。[4.9]、[4.10]、[4.11]、[4.12]
一方、連環度が連続する計量値で、それが複数ある場合は、従来、主成分分析が主に扱われてきた。
しかし、連環度が計量値だけでなく、多数のノミナル変数やランク等の順序を持つオーディナル変数等を含む混在型のデータタイプをもつ問題は、扱える手法はなかった。
ここで、ノミナル変数の問題に限って、前のセクションで扱った多重属性問題を考えて見よう。
例ば質問が多いWebのアンケート調査では、選択肢から答えを選ばせるノミナル変数が複数ある場合でも、全体の結果を理解することは容易ではない。
まず、どの変数同士が独立なのか相関があるのか、その組み合わせをどこまで理解した方が良いのか等意外に難しいのである。
多くの場合、各属性を持ったプロファイルデータを、単純集計したり、それらの関係を理解するために、クロス集計表を作り、それを可視化することがあたかもデータサイエンテストの大事な仕事や役割であるかのような資料を見かける。
例えば、新製品は、どの機能が、どの性能が、どのデザインが、どの年代の、どの職業が、等などの2種づつ属性のクロス集計表を計算し、それをグラフ化するソフトが多用されている。
例えば、エクセルを使えば、簡単に2種のアトリビュートのクロス集計結果をグラフ化できる。
また、最近は、ヒートマップと言われるクロス集計表の値の大小を直接、赤や青のグレイ度付けをすることで、各行の中や、各列の中でどれが大きいか小さいかや、あるいは全体の中でどの行とどの列の組み合わせが大きいか小さいか等が、ぱっと見ただけで目立つように可視化できるのである。
こうして、多種類あるアトリビュートでもその組み合わせの全体のデータから全体を眺めて理解することで、意味のある状況や役に立つ知識を得られやすくなってきてはいる。
確かに、集計表は、それぞれのアトリビュートの分布の概要を理解するために、大切である。また、2種のアトリビュートを組み合わせたクロス集計表も、大切である。
ただ、こうしたクロス集計表は、いくつかの不足や欠点や落とし穴を持っていることを知っておくことも大切である。
例えば、統計学のテキストでは、χ2乗(カイ2乗)検定が使われている。もし、各アトリビュートのアイテム数が少なく、データ数も少ない場合は、検定結果が有意である(2のアトリビュートの独立性が疑わしい)という結果が出にくい。
一方、アトリビュートのアイテム数が多くなるといきなり有意になり易くなる。いわゆるP-値(独立であるとした時にそれが誤りである確率)はどんどん限りなく小さくなってしまう。その結果、すべてのアトリビュート同士の組み合わせを理解しないといけないことが分かるだけで、ではどうするのという問題が残ることも多い。
こうした場合に、対応分析が使われる。また、プロファイルデータが複数のアトリビュートを持つ時は、多重対応分析が使われる。ただ、これらを使う場合のソフトが、多重クロス集計表を使うことが多いため、その後の展開が難しいことに留意が必要である。
このクロス集計表に関する問題には、いわゆるシンプソンのパラドクスという問題があることも注意しておく。[4.13]広津
4◇分る・・・全体を知る、分けて知る、そして総合する
4.1多属性アトリビュート空間に分布するサブジェクト
ここでは、アトリビュート変数が大量にあるとき、サブジェクト・アイテムの全体の分布の構造や情況を理解すること、それによって、サブジェクトの本質、特徴、性質を知ることに挑戦する。
2節までは、アトリビュート変数が1つに限られていた。その場合のプロファイルデータで、サブジェクト・アイテムの分布を、アトリビュートとの関係の中でその分布情況を見た。
2次元なら平面上にn個の点として眺めること出来た。計量値の場合は、2次元に撒布した分布として可視化することができた。
例えば、例のアリストテレスの肉の種類と健康関係する肉の重さの2種の属性の問題である。肉の重さが肉に含まれる不飽和脂肪酸の量であるらしいことで、この健康度と肉に含まれる不飽和脂肪酸の量との関係であることが分かった。この2の計量変数を、食べた人の数でその分布をプロットしたのが[図4.11]であるとする。

[図4.11]
この図における食べる肉の重さと健康度の2種のアトリビュートの関係は、n人のサブジェクト・アイテムを、右上の図のように、 を縦と横軸に取った2次元の図の上に、n個の点としてプロットできる。
この図のように、重い肉を食べている人ほど健康度が下がっているのが分る。
これは、食べる肉の重さと健康度との相関関係を示している。
しかし、これが3種のアトリビュートでは、3次元の立体空間で表現することになる。4次元目も、3次元空間を時間でうごかしてみれば分かるかも知れないが、5次元以上は無理である。
いま、n人に対しQ種の計量値のアトリビュート変数のデータがあった時、それらの変数の相関は、Q個から2個採る組み合わせの数だけの散布図が必要となる。
Qが10種とすると、10から2を採る組み合わせは、10!/(2!X8!)=45枚となる。
しかもこれだけの散布図を見て、それが日本人全体の俯瞰データであるとして、頭にイメージが湧くであろうか?
そこで、連環データ分析では、サブジェクト・アイテムと複数のアトリビュート・アイテムを、元データから次元圧縮で、2~3次元の可視化できる空間に、それも単一の空間に同時に布置する方法を開発した。
この方法の本質は、次元圧縮による情報圧縮である。
また、それは、アトリビュート変数間の関係は、そのアトリビュート変数を持ったサブジェクト・アイテムの分布の仕方であるということである。
もし、分布上で、もし任意の2つのA,Bのアトリビュートを採り挙げたとき、AのアイテムaiとBのアイテムbjとが近いか遠いかが判ればよい。
と言うか、アトリビュート・アイテムaiを持ったサブジェクト・アイテムとアイテムbjを持ったサブジェクト・アイテムが近いか遠いか分かればよい。つまり距離の問題である。
一般に、多次元相関係数等で次元を圧縮して、元のデータを近似することで、2~3次元に情報を圧縮してマップ化する方法は広く用いられている。
ただ、従来は、サブジェクト・アイテムとアトリビュート・アイテムを、距離を保ったまま同じ空間に布置することは禁止されていた。
理由は、この距離を求める方法が見つかっていなかったのである。
この時、それらの距離関係を、原点からの見込む角度距離を使う方法を開発することで、それが可能となったのである。
少し、理屈が難しくなったが、連環データマップを、一目みれば、すぐ理解できるだろう。
4.2多属性のサブジェクト事象の分布とクラスタ分析
プロダクツやサービスの等のビジネスの対象アイテムの集合として、カテゴリーやジャンルや品種や業種や職種等も、調査、研究の対象となる特性を持つ集団と捉えることもある。
さらに、あるテーマを採り挙げたとき、多様で分散したデータと知識を集め、プロジェクトのような、体験的集合知を働かせることができる場で、そのグランドスコープを描き、共有しダイアログをし、コンセプトを集約する必要がある。
この様に、多属性変数を持つサブジェクトの分布は、その変数間に相関関係があり、サブジェクト・アイテムを属性で似たものを集めると、その分布が、幾つかのクラスタを形成するのが自然である。
また、アトリビュート変数間の相関は、その変数を担うサブジェクト・アイテムの分布の形状によって決まるということである。
そして、もし変数間に相関関係のネットワーク、これはヒトの言葉のイメージの距離のリンクと言ったものであるが、の集積された塊りがあれば、それを担うサブジェクト・アイテムも、その意味空間で集積される塊を形成するであろう。それを同時クラスタと呼ぼう。
そして、こうしたクラスタは、クロス表というネットワークデータを少数次元で近似する次元圧縮による情報圧縮法によって得られた空間上に、同時布置できれば、同時クラスタが可能になる。
これは、サブジェクト・アイテムの母集団をNECEに分けて知ることと、潜在的なサブジェクト・アイテムやアトリビュート・アイテムを含んでそれが、再構成の可能性があることも示唆する。
そのことが可能である理由は、サブジェクト・アイテムの多次元分布が、多属性変数の相関係数によって説明できることである。
そうしたクラスターは、その構成メンバーが共通に担うある特徴としての言葉がそれに与えられたとき、それがカテゴリーやコンセプトとして、ヒトの前に現れてくる。
つまり、コンセプトやカテゴリーは、そうした下部構造によって規定されているのである。
この同時クラスタ分析が重要な役割を果たすようになる。そのとき、多次元のサブジェクト・アイテムの意味の分布への展開が可能なるのである。その応用法がCCチャート(Concept Compass Chart)であるが、後ほど詳述したい。[4.13] 唐澤
ここまでくると、事象の本質という問題は、かなり明確になってくる。つまり、事象は集合であった。事象の本質は、個々のサブジェクト・アイテムではなく、集合の分布から切り分けられた、クラスタの特徴で染め上げられた言葉としてのカテゴリーやコンセプトと、その大きさや位置関係で全体に位置付けられる。
そして、クラスタリングの機能は、膨大な次元の膨大な量のデータであっても、4クラスタなら2ビット、8クラスタな3ビットで表現できる情報圧縮機能である。
例えば、年間数十兆円売り上げるウオールマートは、顧客を1000位にクラスタリングして、顧客の動向分析をしているといわれるがそれでも9ビットあれば、識別可能なのである。
4.3具体的な事象をクラスタ分析で理解しよう
事象を理解するため、サブジェクト・アイテムとその多種のアトリビュート変数とのいわば共生関係を、クラスタで理解するために、具体的な例を挙げよう。
1)食の好みをアンケートで調べる
以上に見てきたように、サブジェクトの本質を探索する次元圧縮し、クラスタリングする多変数アトリビュートの簡単な例を考えよう。
例えば、日本の食は、世界中の料理のほとんどをカバーしているといわれる。では、食に関し、日本人は、どのような好みを持っているだろうか?
知りたい対象は、日本人の食の好みである。この場合、母集団は日本人で、特性は、食の好みである。
多くの場合、母集団やカテゴリーを全ての個々の特性を知ることが難しいし、個々の特性よりも、集団の分布状態を知りたいのである。
知りたいのは、この国の12、000万人の個々のヒトの好みではなく、日本人の全体の食の好みである。
この様な無限に近い母集団を調べるのに、全員を調べるのではなく、全体像をサンプリングで知る方が正確である。
以前、牛肉のBSE問題で、US側はサンプリングの方が正確だとの姿勢を崩さず、日本側は全頭検査を主張して争ったことがあった。
もし、関東圏の食の好みを知りたいのであれば、放送局の食レポ番組の視聴率データで、どのような食の料理番組が人気があったかを、600人のサンプルで調査している会社からデータを買うことも可能である。
この場合、食の好みの内容として、何を知りたいのか、それの本質は、どのような属性なのか、を理解すれば良い。つまり物事や事象の本質は、属性のことである。
もし、日本人の食の嗜好性を質問されたとき、どう答えたらよいであろか?
質問の目的や意図は、日本人の食の好みの内容、ジャンルとそれを好きな人々の割合であろう。
つまり、全体を分けて、どのようなジャンルを好きな人が何人位居るか、が判れば、分ったということになろう。
”分る”と言うことは、”分ける”ということと、何で分けるか、ということである。
具体的に、簡単な食の嗜好に関するアンケートの例を見てみよう。
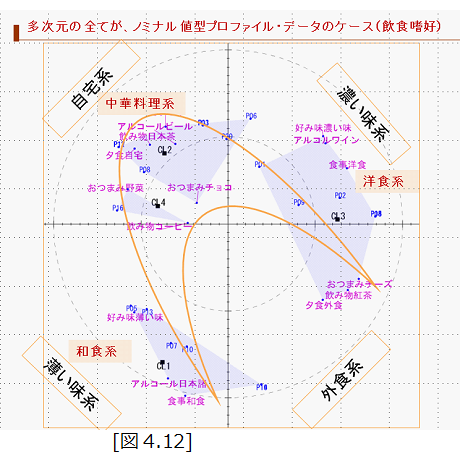
これは、20人のサラリーマンに対し、食事とおつまみと、アルコール飲料とノンアルコール飲料の好みを尋ねたデータである。
このデータは、クロス表で、表側に20人分の20行を用意し、質問項目の種類は、食時が3種、アルコールが3種、食後の飲み物が3種、おつまみが3種の計12列の[1、0]のデータである。
これを、連環データ分析に掛けて、マップ化し、似たものをクラスタリングした結果が[図3.2]である。
図には、食の好みの属性アイテムが朱色のフォントで、アンケートに答えた人が黒字で20人が布置されている。
これで判るのは、料理の種類も似たものがあつまっており、その好みも、似たものが集まってクラスターを造っているということである。
実際は、4個にクラスタリングしたが、全体は、大きく3個のクラスタであると居える。
そして、もし、これが日本人からのランダムなサンプルであれば、中華系に9/20=45%でこれがマジョリティで、残りを洋食系に5/20=25%、和食系に6/20=30%がいわばマイノリティで、好みが分布していると言えるであろう。
さらに、このクラスタの構成から、日本人は、外では洋食か和食を御馳走として、自宅では中華系としている。外食時は、洋食ではワインで、和食には日本酒で、自宅では中華系でビールでマリア―ジュしているようだとしても良いのではないだろうか。
このマップで、日本人の食の嗜好の本質に迫れたとすれば、それは、サブジェクトと、アトリビュートのいわば相互相関性とも言うべき性質を使っているからである。
まず全体を個人単位(サブジェクト・アイテム)で捉え、漏れなく、重複なく、捉えたこと。
それをまた、似た個人同士をクラスタリングし、その結果、属性でも見てまた似たアトリビュート・アイテム同士を、漏れなく、重複無く、分類したことであろう。
結局、アトリビュート変数間の相関は、その変数を担うサブジェクト・アイテムの分布の形状によって決まるということである。
そして、その意味の構造を読んだこと。そして、経験に照らし、一貫性が有って、違和感を感じないということではないだろか?
2)個人の価値観をどのようにして分るか
分るということを、全体を理解するという、ことで、意味という尺度を取り込んで、そのクラスタという視点から見てきた。
こうした理解に、一貫性という意味を考えてみたい。
2000年ころ、USのPOMの学会で、GMとトヨタのスタッフ達と、ランチョンミーティングをやったとき、なぜ日本車はUSで成功したのだろうか?という話題となった。
若いGMのコーポレートプランニングのスタッフは、”それは、品質である”と答えた。トヨタのスタッフの答えも、”その通り!”と力強く同意したことがあった。
”私は、それも大切で必要な要因ではあったが、十分な条件でなない、それだけでは、なぜソニーもトヨタも小型なプロダクツで成功したのかが説明できない”、”それはアメリカ人の価値観が大きく変わったからではないか”と指摘した。
アメリカ人の価値観という抽象的な事象の本質をどのように把握し、説明したら良いだろうか?
価値観やライフスタイルという下手をすれば、2億人も居て、日本より多様なヒト達の全体のまさに多次元な分布を理解し、その変化やトレンドを理解する必要がある。
従来、USのマーケティングは、世帯を家族構成や年齢、住所、職種や世帯取得等のいわゆるデモグラフィック(物理的、ハードな)属性で層別してデータを採ってきた。
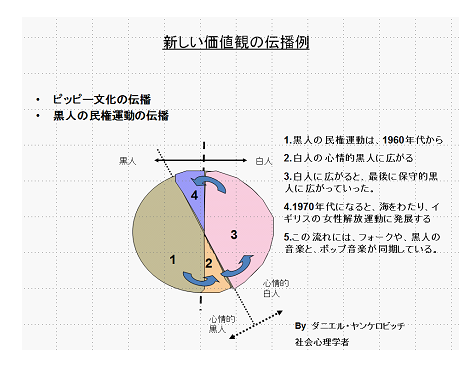
それを、ダニエル・ヤンケロビッチが、社会心理学的属性によるクラスタリングという手法を持ち込んできた。その彼の結論は、衝撃的であった。[4.14]D.Y.
古い価値観は、以下のような考え方であり、
・性差への意識
・物質所有へのこだわり
・古い家族主義
・社会的成功を示すための財貨志向
・古い年長制度へのこだわり
・皮相的効率主義、合理主義
・所属組織、社会的地位
・権威主義
一方。新しい価値観は、
・優しさ、平等主義
・経験の所有を大切にする
・友人を大切に、
・離婚の許容
・環境への貢献
・個人の尊重
・感性を大切にする
・自己実現、自己充足、自己表現
・今日主義、レジャー意識
等であるとした。
そして、クラスタリングし、さらにロジャーズのこれらを先進尺度に擬え、価値観の普及と伝播のプロセスを説明した。
ベトナム戦争は、アメリカ人に大きなインパクトを与えた。社会心理学的アプローチで、わずか50問足らずの質問で、7から8にクラスタ分析をした。
その結果、全米2億人のアメリカ人を、社会的価値観という漠然とした概念で、7から8に分類できたのである。
それまでの、ピューリタニズムの価値観が崩壊し、ワークハードやアメリカンドリームが崩れ、例えば、日曜日に家族全員が大きな車にのって教会に行く習慣が尊ばれなくなった。テレビは家具の要件を求めないスタイルがソニーから持ち込まれ、個人個人が同じソプドラマやバラエティショウを見るのでなく、個人が自分の部屋でパーソナルテレビで好みに合ったプリグラムを楽しむようになった。日曜日には、家族がそれぞれ、自分用の小さな車で、好きな方向に家から走り去るようになったのである。努力して働いて、世帯のステータスを示す大型家具や大型者は、逆に時代遅れのステイタスとなったのである。
しかし当然、そうなると、価格はより安く、故障は少なくないと助けてくれる家族もいないから困るのである。
逆にいえば、あるヒトがあなたの社会的価値観は?と問われたとき、「私は、誰でもない、私の価値観は、これこれこうである」と主張したいとする。しかし、全米の平均と比較してどうか、また指示政党や好きな飲料の種類やブランドへのこだわりとして等とすると取り留めが無くなる。
しかし、こうした一人一人のアトリビュート変数には、相関がある。こうした相関関係を凝縮して、マッピングするとクラスタ状態が出現するのである。
つまり、社会全体を分けることにより、その個人がどのような社会的価値観を持っているかが、理解できるのである。
ヤンケロヴィッチは、こうした社会的価値観を幾つかの質問を継続して調査を続けた。
一貫性は、例えば時系列で、その遷移が納得できれば、それでも良いであろう。
こうした価値観変遷と推移を上手く説明したのが、[図3.13]である。
[図4.13]
4.4イメージの伝達法としてのメタファー
ヒトはある事象についてイメージを持っているが、言葉にならなくても、ヒトはそれを意識していて、ヒトに伝えたい場合がある。それが音楽でも、絵画でも、料理でも、ダンスでも良い。
しかし、「事象のイメージの本質を正確に、ヒトに伝えることができるのは、言葉しかない。またその言葉も飾る言葉と喩える言葉しかない。」これは、ソニーのデザイン本部長を勤めた渡辺英雄の言葉である。
例えば、ワインの味を、ソムリエは、どう説明するだろうか?
良くあるのは、色や香りや見た目は花等に喩え、タンニンの渋みや熟成度等の重みは、フルボディやミディアムボディや華やかさなど女性に喩えたりする。
こうした“意味”は、定義されたサブジェクトの集団とアトリビュートの集団におけるメンバー同士を、一つの世界(アイランド)のMAP上で関連させた命題である。
メタフォーによる“メッセージ”は、複数のアイランドからのオブジェクトを、自らのビューポイントにインポーズした多重空間で語られる命題である。
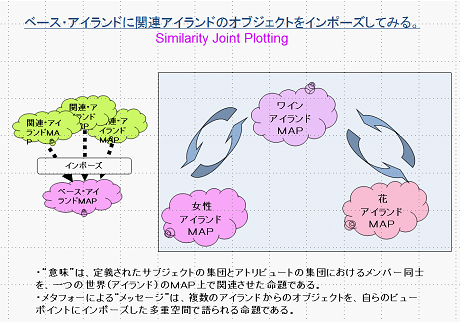
[図4.14]
このとき、ヒトは、ベースとなるワインというアイランドのランドスケープを説明するととき、喩える花や女性の形容詞からなる意味のアイランドのランドスケープを借りてきている。そして、重要なことは、それぞれのランドスケープに布置された事象アイテムの分布の中心を会わせて重ねている。また事象アイテムの分布の意味のスケールも調整している。さらに、実は、意味の向きまで調整して説明しているのである。
そして、こうした多重空間で語られる命題を、ヒトは共有できるのである。
こうした、”ワインの味”という事象の本質は、言葉によって人々が共有できるといえるように思われる。
これを、別なイメージで説明すると、事象の本質は、立ち位置を変えて眺めてみる時のランドスケープで語ることが可能である。
人間は、宇宙の端のごく小さな銀河系に棲んでいる。その銀河系の端の小さな太陽系の地球と言う小さな惑星に棲んでいる。
しかも日本人は、極東と言われる小さな島に暮らして、日々の細やかな悩みや喜びを感じながら過ごしている。
それまで、自分たちが、地上という、大地の上に真っ直ぐ立って、その周りを星達がぐるぐる回っている神が造ってくれたと思っていた秩序が崩れたのは、14世紀のペストが人びとに不条理な死に直面させ、神という権威をも死滅させ、その直前に、ラテン語に翻訳されたペルシャやアラブやギリシャの科学的世界観の秩序がもたらしたルネッサンスからだったと言われる。
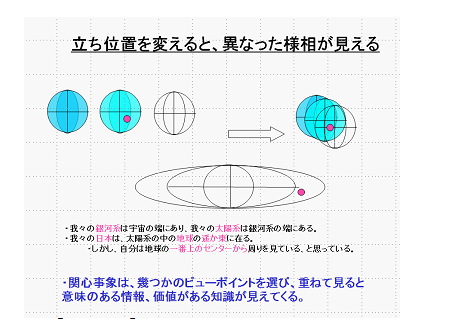
イメージの近さを不変性で捉まえると相関性となる
科学という仮説は、不変性を大切にしている。物事の本質は、敷衍性と不変性(Invariant)であることを求める。
意味の相関性が物事の本質に関わっていることを見てきた。
相関関係は、因果関係というフィクションより技術的で、操作的である。
相関関係は、計量的属性変数を持った2つの事象の集団の性質である。片方の属性の値が増えたとき、もう片方が増えるか減るか、あるいは変わらないかの関係である。
もし、片方の集団の属性値に一定の値を足したり、一定の値を掛け、他方に何もしない場合でも(これはアフィン変換と呼ばれる)相関係数は不変である。
連環データ分析は、各別のアイランド(通常は各別のクロス表)で表すが、こうした複数の属性の意味の相関関係を表現している。
サブジェクトやテーマが与えられたとき、同時クラスタの大切な応用例としてグラウンデッド・セオリーを挙げよう。
あるテーマについてのアイデアの意味の構造を理解するには、グラウンデッド・セオリーのローチが有効である。[4.14]紺野
この場合、データがテキストになるので、アイテム変数をキーワードとし、1000語選ぶと、アトリビュート・アイテムは、1000次元となる。
グラウンデッド・セオリーは、テーマとするフィールドで、エスノグラファー等が観察し文章化したデータをKJ法のようにクラスタ化し、それにラべリングするが、これをクラスタのオープンコーディングと呼んでいる。
そして、クラスタを構成する意味空間を直交軸でその意味構造にまたオープンコーディングしこれを軸足コーディング(アクシャル・コーディング)と呼んでいる。
さらにクラスタの関係をオープコーディングし、関係性コーディング(セレクティブ・コーディング)する。
これは、社会学者のバーニー・グレイザーとアンセルム・ストラウスによって提唱された、質的な社会調査の一つの手法であるが、ワークショップやブレインストーミング等で出されたアイデアを分析するのに便利である。
4.5イノベーションを駆動するデータ分析の新領域
そしてここでは、因果関係より対応策に役立つ相関関係を採り挙げたい。
ただ、相関という概念は、2種の変数に限られたものであったが、サブジェクトとして採り挙げた変数全体のいわば総合的相関関係と言った概念が必要になってくる。
すでに、1.4節では、情報量の大キサに関しての属性データタイプの5類型を見てきた。
そして、属性の種類が多い程、事象のリアルファクトやバーチャルファクトの本質に迫ることができることも理解してきた。
また、たとえ、個別事象に関することであっても、その集合の位置づけで、その個性や特徴が分るということも、理解してきた。
では、多くの属性逹が、サブジェクト・アイテムにまとわりついたとき、それらの2種類の属性変数間のそれも計量値変数しか定義されていない相関関係をどのように理解したらよいであろうか?
例えば効果的な施策を考えてみよう。
政府はコロナ対策として、マスクを北海道に配ったが、実は東京こそが優先されるべきであったし、もっと別な属性からスーパのレジ等の職業や職種に配布すべきこと等が判ったはずである。
データ無き施策は、それこそ闇夜に竹藪に撃つ鉄砲の類である。玉は何所に当ってどこに向かってくるか、こちらに向かってくるかも判らない
放送局の視聴率は、300世帯から関東圏でも600世帯のサンプルで[1 or 0]で測定されているに過ぎない。もし視聴質を見たいなら、計量値で100世帯でも良いのである。
例えば、PCB検査キットの不足等や検査に押し寄せるパニックを怖れる必要もなく、地域別に300人ずつサンプリングして見れば、もっと的確な施策が打てるはずである。
これが、バイオマーカ等の画像、例えばCT画像であれば、情報量は圧倒的に多く、肺炎等の診断は、かなり的確にでき、不足するPCBの議論に足を取られることなく、より的確な施策を立案できたはずである。
ただ、たとえ属性が一つであっても、情報量の多い計量値の場合は、計量値を幾つかにセグメント化した複数の属性アイテムと個々のサブジェクト・アイテムとの連環度[1or 0]に整理できることも、他の変数タイプでも、ノミナル変数タイプに変換できることを、すでに我々は理解している。
では、こうした、アトリビュート変数の情報量の多い領域と、アトリビュート変数の多い領域と、さらにキー・アトリビュート変数の多い問題が、これからイノベーションを支援するためのデータ分析の領域となるであろう。その観点から眺めてみよう。
すでに見てきたように、従来のデータ解析法は、ノミナル型やオーディナル型や、計数型や計量型などの情報量が少なく、アトリビュートも少なく、また特性値としてのKPA(キー・パフォーマンス・アトリビュート)変数の数も限定的な①が中心的課題領域であった。
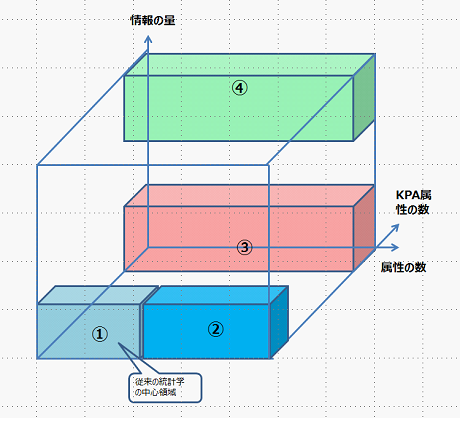
[図4.16]
しかし、既に見てきたように、IoTや、Web調査や、テキストおマイニング等で、いま、急速に属性の数が増え②の領域が増えてきている。
また、従来は、KPA等が一つの変数で、それも良否や、生死等のノミナルや計数値や計量値であった。しかし、KPAは、必ずしも1つとは限らない。ハードの設計問題でも、コストや品質はトレードオフで、その調和が問題となる。
また、サービスビジネスでは、顧客満足度と共に、従業員満足度が重要であるし、仲介者等が居る場合も多く、ステークホルダーが複雑になると、KPIも多くなり、③の領域が大切となる。
サービスの高度化が進み、ヒトの6感に対する訴求満足度を高めようとすれば、今後語は、眼耳鼻舌身意などの調節アクセスする仕組みやブラウザー等のメディア環境のデザインニーズが増えてくると、④の領域が大切になってくるだろう。
さて、新型コロナで3つのシチズン・ソサエティと、ビジネス・ソサエティと、マネジメント・ソサエティが揺らいでいる。
またその与件たる環境資源コスモスとメディア資源コスモスの揺らぎは、全てのソサイエティが目指すエドモニアへの新しいコスモスに向けて、何かの障壁を乗り越えようとしているのだろう。
14世紀のペストでは、宗教の権威が揺らぎ、科学が台頭した。9.11ではビジネスの権威が揺らぎ、3.11では科学の権威が揺らいだ。今回挑戦を受けているのは何であろうか?
▼△▼△▼△▼△▼△▼△▼△▼△▼△▼△▼